-
Verifying Vision-Language Alignment with Cross-Attention Map (feat. DINO)Machine Learning/Multimodal Learning 2022. 4. 28. 01:33728x90
최근 Vision Transformer를 self-supervised로 학습하는 방법들이 활발히 연구되고 있습니다. DINO는 그중 하나로 제안한 방법으로 학습한 모델의 self-attention map을 시각화한 결과, 이미지 속 객체를 뚜렷하게 구분하는 것을 확인했습니다. Semantic segmentation 정보를 주지 않았음에도, 아래와 같이 객체를 잘 구분해 많은 관심을 받았습니다.
저자들은 Vision Transformer의 마지막 layer에서 [CLS] 토큰과 다른 patch들 사이의 self-attention map을 시각화했으며, 특정 객체 위치에 해당하는 patch와 다른 patch들 사이를 시각화했을 때도 관련 있는 부분들의 attention이 높았습니다.
자세한 내용은 Emerging Properties in Self-Supervised Vision Transformers(ICCV 2021)을 참고해주세요. [
blogpost] [arXiv] [Yannic Kilcher's video]
Self-attention from a Vision Transformer with 8 × 8 patches trained with no supervision Cross-attention visualization
Vision domain 뿐만 아니라 Vision-Language domain에서도 Transformer가 활용되고 있으며, ALBEF(NeurIPS 2021, Spotlight)와 같은 최신 논문에서는 Transformer의 self-attention이 아닌 cross-attention으로 이미지와 언어 사이의 정보를 통합했습니다. DINO의 결과에 적지 않은 충격을 받고, self-attention 시각화를 통한 이미지 patch들 사이의 관계 파악 방식을 멀티모달로 확장하고 싶었습니다. 멀티모달 transformer의 cross-attention map에 나타나는 텍스트 토큰과 이미지 patch들 사이의 관계를 확인할 수 있을 것이라고 생각했습니다.
Vision-Language(VL)에 대한 학습이 잘 이루어졌다면, 문장의 각 단어와 이미지 내 객체 사이의 alignment 정보를 cross-attention map이 담고 있을 것이라는 가설을 세웠습니다. 그리고 COCO 데이터셋의 텍스트-이미지 쌍 데이터에 대해 ALBEF 모델의 cross-attention map을 시각화한 결과, 다소 noisy 하지만 단어와 객체 사이의 상관관계를 파악할 수 있었습니다.
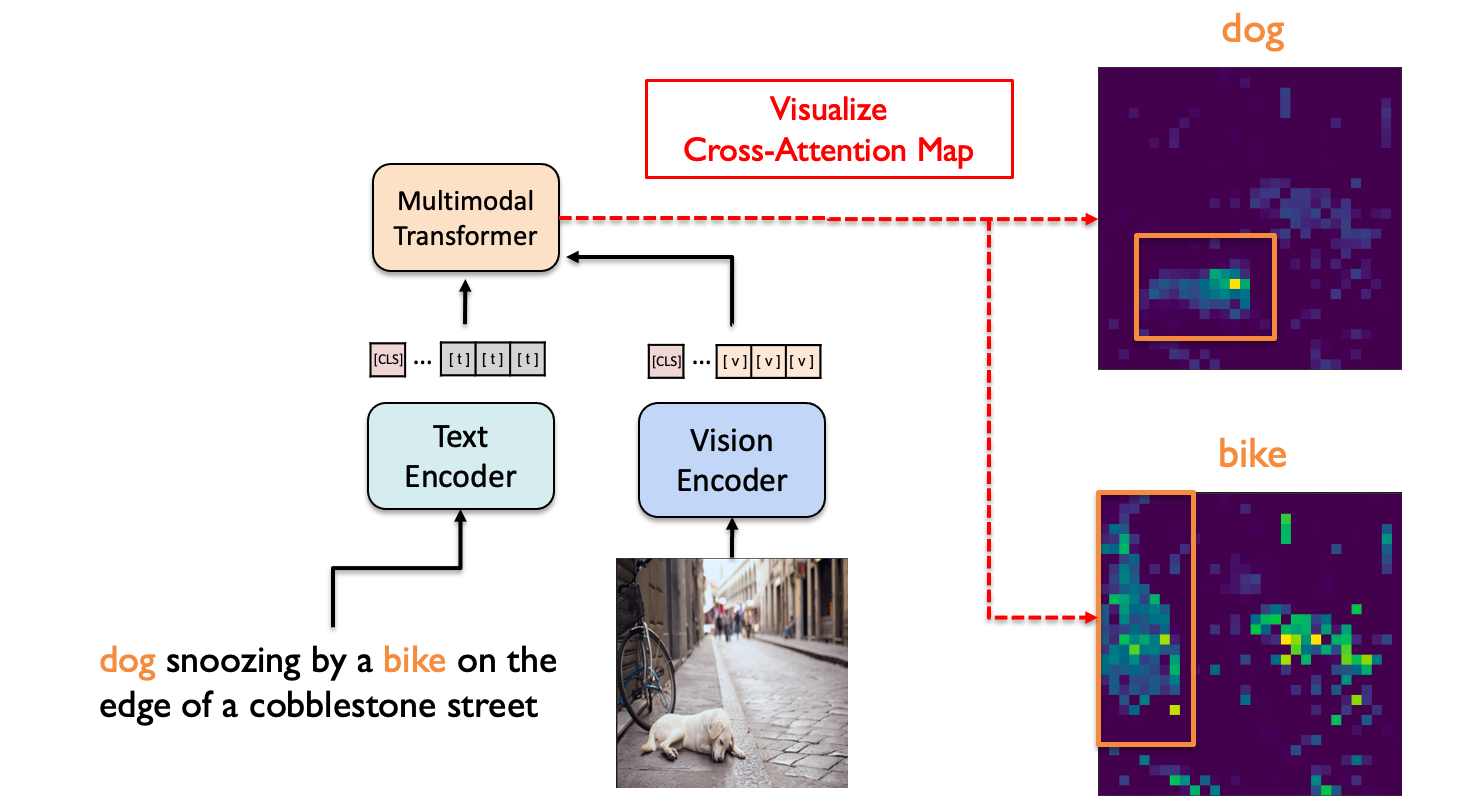
Overall process Method
Self-attention은 query, key, value 모두에 같은 input을 넣어주어 input 내 element들 사이의 관계를 학습합니다. ALBEF와 같은 VL domain의 멀티모달 transformer는 cross-attention의 query에 text feature를 input으로 주고, key, value에 image feature를 넣어주어 text와 image 사이의 관계를 학습할 수 있습니다.
## VL-DINO/models/xbert.py line 276~297 ## hidden_states는 text encoder의 output으로 text feature를 뜻함 mixed_query_layer = self.query(hidden_states) is_cross_attention = encoder_hidden_states is not None ## key, value의 input은 encoder_hidden_states로 vision encoder의 output if is_cross_attention: key_layer = self.transpose_for_scores(self.key(encoder_hidden_states)) value_layer = self.transpose_for_scores(self.value(encoder_hidden_states)) attention_mask = encoder_attention_mask ## self-attention은 key, value, query 모두 hidden_states로 text encoder의 output else: key_layer = self.transpose_for_scores(self.key(hidden_states)) value_layer = self.transpose_for_scores(self.value(hidden_states)) query_layer = self.transpose_for_scores(mixed_query_layer)위의 그림을 예로 들면 'dog snoozing by a bike on the edge of a cobblestone street' 이라는 문장이 text encoder를 거쳐 나온 textual feature가 query로 들어가고, '강아지가 자전거 옆에 누워있는 이미지' 가 vision encoder를 거쳐 나온 visual feature는 key, value로 들어가는 것입니다.
이 때이때 query의 'dog'와 key인 이미지 patch 사이의 내적을 통해 cross-attention 값을 구할 수 있고, 이를 시각화한 것이 위의 그림에서 오른쪽 위에 있는 attention map입니다. 이때 Transformer는 멀티헤드를 가지기 때문에 각 헤드들이 구한 attention map을 평균해 나타냈습니다. 멀티헤드의 목적이 다양한 시각으로 input을 인식하는 것이기 때문에 배경 부분에도 attention 값이 어느 정도 높게 나타나지만, 강아지의 영역을 제대로 구분하는 것을 확인할 수 있습니다.
## VL-DINO/visualize_attention_upper.py line 257~280 cross_attn_map=model.text_encoder.base_model.base_model.encoder.layer[block_num].crossattention.self.get_attention_map() ## cross_attn_map dimension : ## (Batch size) x (Multi-Head) x (Text token) x (Image patch) nh = cross_attn_map.shape[1] # number of head nt = cross_attn_map.shape[2] # number of text ## head-wise average attentions = cross_attn_map[0, :, :, 1:].mean(0).reshape(nh, -1) ## 각 text token의 attention map attentions = attentions.reshape(nt, w_featmap, h_featmap)Usage [ link ]
- DINO github을 참고해 환경설정을 해줍니다.
- ALBEF github에 있는 사전학습된 모델을 다운로드합니다.
- visualize_attn_upper.sh 파일의 path 수정 후 실행합니다. (다양한 이미지-텍스트 쌍으로 실험 가능합니다.)
sh visualize_attn_upper.shConclusion
해당 결과를 통해 supervised 방식으로 단어와 이미지 내 객체를 bound box 등으로 매핑해주지 않아도, self-supervised learning 과정에서 두 모달리티 사이의 연관성을 학습함을 알 수 있습니다. 객체와 관련 없는 부분도 높은 attention 값을 가지지만, 이는 모델이 이미지를 이해할 때 객체뿐만 아니라 배경도 함께 고려하는 것으로 해석할 수 있습니다. 혹은 멀티헤드를 평균 내 시각화했기 때문에 특정 헤드들은 bias 되어 있어 특정 단어들에 대해서 비슷한 영역을 참고할 수 있습니다. 하지만 다른 이미지를 볼 때는 그 헤드가 중요한 역할을 할 수 있기 때문에 더 다양한 실험을 통한 분석이 필요해 보입니다.
실제 연구를 진행하며 고안한 모델의 학습이 잘 진행되었는지 시각화를 통해 확인할 수 있었고, attention distillation 방향의 발전 가능성도 확인했습니다. 최근 CLIP, DALL-E 등 vision-language domain에 대한 관심이 높아지고 있는 상황에서 해당 시각화 방법이 멀티모달 transformer를 해석하고 이해하는 데 도움이 되길 희망합니다.
728x90'Machine Learning > Multimodal Learning' 카테고리의 다른 글