-
[논문 리뷰] ALBEF - Align before Fuse: Vision and Language Representation Learning with Momentum Distillation (NeurIPS 2021, Spotlight)Machine Learning/Multimodal Learning 2022. 4. 20. 21:31728x90
NeurIPS 2021의 spotlight 논문으로, Vision-Language Pre-training(VLP) domain에서 multimodal encoder 앞단에 pre-alignment part를 추가한 새로운 framework를 제안했습니다. 당시 다양한 VL task(IRTR, VQA, NLVR2 등)에서 SOTA를 달성했고, 이후에 CVPR 2022, ICML 2022에서도 ALBEF를 기반으로 한 논문이 많이 제출되었습니다. [ Paper / Code ]
BERT, ViT, CLIP, Knowledge distillation(KD), VLP domain에 대한 이해를 전제로 review를 작성했습니다.
1) Abstract & Introduction
최근 다양한 vision-language(VL) task에서 Large-scale VL representation learning이 promising한 성능 향상을 보여주고 있습니다. 기존 방법들은 transformer-based 멀티모달 인코더를 채택해 visual input과 word token을 input으로 받아 jointly 학습했습니다. 하지만 이때 visual input과 word token이 align 되어 있지 않기 때문에 (서로 전혀 다른 embedding space를 구성) 멀티모달 인코더가 image-text interaction을 학습하기 쉽지 않았습니다. 이러한 한계를 개선하고자 Contrastive learning으로 학습하는 pre-alignment 과정을 multimodal encdoer 전에 추가하는 것이 contribution 입니다.
현재 많은 이미지-텍스트 대용량 데이터는 보통 web 데이터로, 이미지와 텍스트 사이에 서로를 잘 설명하지 못하는 noisy한 데이터가 많이 존재합니다. 이러한 한계를 개선하고자 ALBEF의 저자들은 Noisy web data 로부터 더 좋은 feature를 추출하고, one-hot label이 갖지 못하는 informative feature를 얻기 위해 momentum model로 pseudo-targets을 만들어 모델을 학습하는 momentum distillation(MoD) 제안합니다.
- VL task : Image-text Retrieval(검색), Visual Question Answering(VQA) 등
- Large-scale VL representation learning : UNITER, ViLT, SOHO, CLIP 등
- Visual input : object detection을 통해 얻은 region-based image features인 경우가 많고 이는 많은 computational cost 필요하다는 단점 있음, 이 단점을 해결하기 위해 CNN-based embedding(Pixel-BERT, SOHO) 혹은 ViT와 같은 linear embedding(ViLT)으로 visual token을 얻음
- Word toekn : BERT와 같이 linear embedding 방식으로 얻음
2) Method
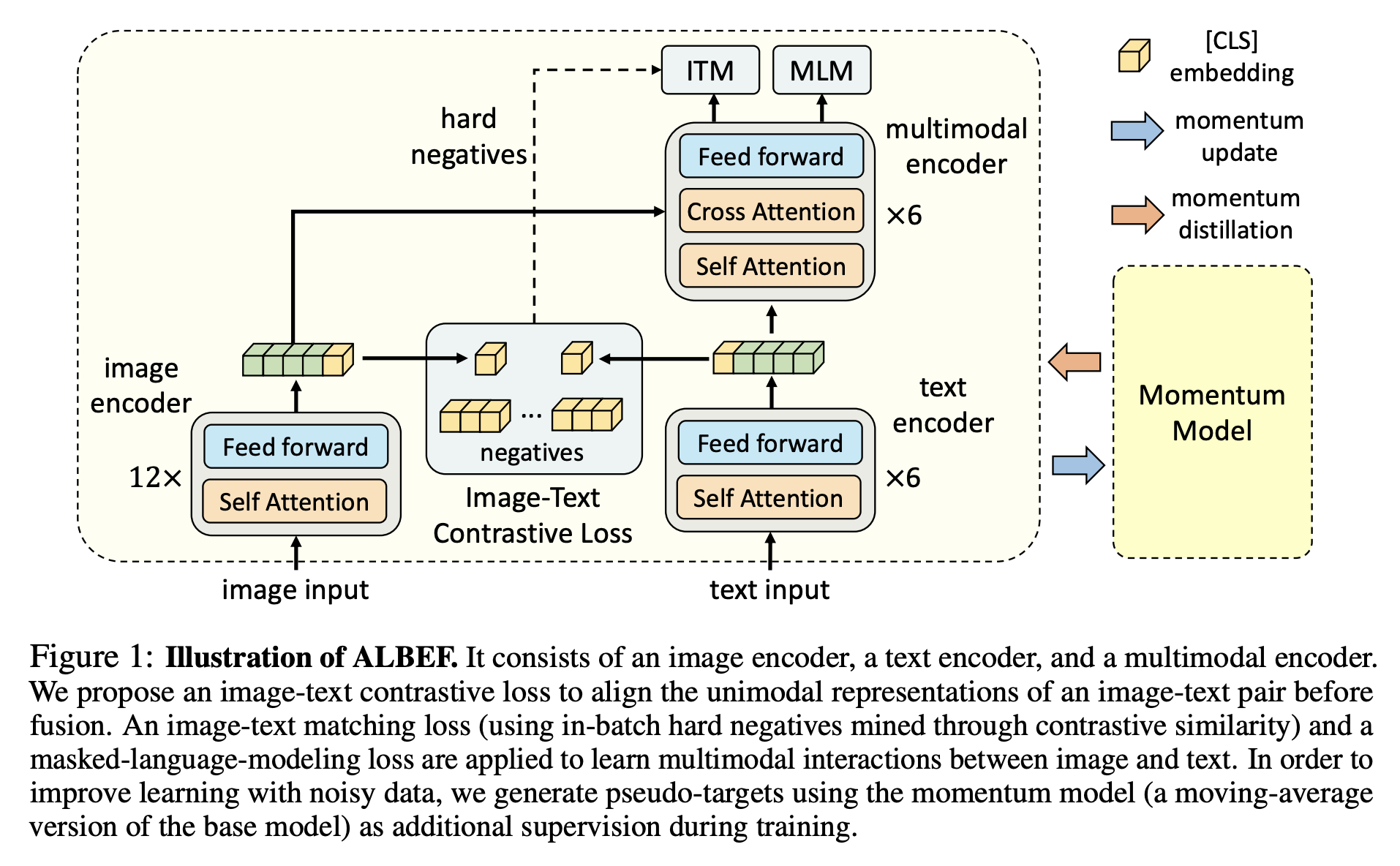
2.1) Model Architecture
- Image encoder(이미지 인코더) : ViT - 12 layer visual transformer, pre-trained on ImageNet-1k
- Text encoder(텍스트 인코더) : first 6 layers of the BERT(pre-trained)
- Multimodal encoder(멀티모달 인코더) : last 6 layers of the BERT(pre-trained)2.2) Pre-training Objectives
Image-Text Contrastive Learning(ITC)
멀티모달 인코더에서 image, text feature를 fusion 하기 전 unimodal encoders를 학습하는 것을 목표로 합니다. ITC의 학습 loss는 CLIP과 유사하고, image input과 text input의 [CLS] token에 대한 embedding feature만으로 loss를 계산합니다. 즉, 같은 image-text pair(positive)로 부터 얻은 feature는 cosine similarity가 높아지도록, 다른 image-text pair(negative)로 부터 얻은 features는 similarity가 낮아지도록 학습합니다. 만약 batch 가 64라면, 하나의 image embedding에 대해 같은 pair인 text embedding은 similarity score가 높아지게, 나머지 63개의 negative text embeddings은 score가 낮아지도록 학습하는 것입니다.
Masked Language Modeling(MLM)
이미지와 mask를 씌우지 않은 contextual text를 활용해 mask 씌운 단어를 맞추는 objective 입니다. BERT와 같이 15%의 확률로 문장 내 단어를 [MASK] 토큰으로 대체합니다.
→ 저희 논문에서 15% 보다 확률을 높였을 때(50%) VLP(Vision and Language Pre-training) 학습에 더 도움이 된다는 것을 보였습니다. 추후 공유하겠습니다.Image-Text Matching(ITM)
image-text pair가 positive(matched)인지 negative(not matched)인지 예측하는 objective 입니다. 멀티모달 인코더의 [CLS] output embedding(joint representation of the image-text pair)을 fully-connected layer를 거친 후 softmax로 image-text matching 여부를 예측합니다. 이때 batch 내에서 negative sample을 선택할 때 random으로 고르는 것이 아니라 image 또는 text와 유사한 semantic을 가지는 hard negative sample로 ITM을 학습합니다.
저희는 이러한 intuition을 확장하여 hard negative sample의 중요성을 확인 및 강조하고, in-batch 내에 유사한 pair를 더 많이 존재하게 하는 sampling strategy를 제안했습니다. ALBEF와 비교해 1/3 epoch의 학습만으로 거의 비슷하거나 더 좋은 성능을 얻었습니다. 현재 review를 받고 있으며, 추후에 공유하겠습니다.
→ 강아지에 대한 image일 경우, 아예 관련 없는 빌딩, 자동차 같은 text를 negative sample로 주는 것이 아니라 의미상 관련 있는 고양이, 산책 등의 text를 선택합니다. 관련 없는 pair를 통해 학습할 경우 negative로 판단하기 쉽기 때문에 모델이 디테일한 정보까지 학습하지 않을 수 있습니다. 하지만 의미상으로 유사하지만 일치하지 않는 pair를 비교할 때는 fine-grained한 detail까지 잘 구분해야만 정답을 맞출 수 있습니다.ITC 학습 과정에서 image-text similarity를 계산하는데, hard negative sample은 이를 활용해 추출합니다. 예를 들어, 하나의 image sample에 대한 negative text sample을 고를 때, 원래 positive pair에 해당하는 text를 제외하고 batch 내 나머지 text들 중 similarity가 가장 높은 sample을 hard negative sample로 선택합니다.
2.3) Momentum Distillation
Pre-training에 사용하는 image-text pair의 경우 web data가 대부분이며, poitive pairs임에도 weakly-correlated 인 경우가 많아 굉장히 noisy 합니다. 또한 MLM과 ITC를 학습할 때 one-hot label을 사용하는데, 아래 그림 예시와 같이 이미지를 더 잘 설명하거나 의미상으로 틀리지 않은 단어가 있을 수 있고(MLM), negative pair가 아님에도 ITC에서 negative로 여겨 similarity score가 낮아지게끔(embedding space 상에서 멀어지게끔) 학습할 수 있습니다. 이러한 문제를 해결하기 위해 momentum model로 부터 pseudo-target을 만들고 one-hot label 만으로 얻기 힘든 정보들을 학습합니다.
momentum model : 기존 모델로부터 exponential-moving-average로 업데이트. KD에서 teacher에 해당하는 모델이며, image-text input을 momentum model에 forwarding 하고 그 output이 pseudo-target이 됨

첫 번째 사진에서 MLM 학습 시 “polar bear in the [MASK]” 에서 [MASK]의 원래 답인 wild 를 맞춰야 합니다. 이때 image와 masked text input을 momentum model에 forwarding 했을 때 [MASK]에 대한 답으로 zoo, pool, water 등을 예측합니다. 이 정답들은 충분히 타당하며 이미지를 잘 설명하는 답들이지만, wild 만을 정답으로 하는 one-hot label의 경우 이러한 좋은 정보들을 학습할 수 없습니다. 이처럼 ALBEF에서는 momentum model의 output을 soft label(pseudo-target)로 여겨 momentum distillation을 해주어 downstream task에서의 성능 향상을 보여줍니다.
ITC 학습시에도 momentum distillation으로 하나의 positive sample만 가까워지게 하는 것이 아니라 의미상 유사도를 고려하여 embedding sapce를 생성합니다. 이는 weighted contrastive learning으로 이해할 수 있습니다.
3) Experiment
3.1) Pre-training
- 4M dataset : COCO + VG + CC + SBU
- 14M dataset : COCO + VG + CC + SBU + CC12M
- 30epoch pretrain → 각 downtream task에 맞게 finetuning
- Loss = ITC_MoD + ITM_hard + MLM_MoD위의 4M, 14M 데이터셋 다운로드 방법을 아래 포스트를 통해 공유합니다.
3.2) Downstream task
IRTR
1.2B(12억) 데이터로 학습한 ALIGN과 비교했을 때 14M(1400만) 데이터셋으로 학습한 ALBEF가 더 좋은 성능을 보입니다. fine-tuned 결과뿐만 아니라 zero-shot 결과도 CLIP, ALIGN과 비교해 더 좋은 성능을 보여줍니다.

2. VQA / NLVR2 / SNLI-VE
다양한 task에서 모두 SOTA를 달성한 것을 보여줍니다. ALBEF에는 나와있지 않지만, SNLI-VE의 경우 label이 noisy 하다는 지적이 있어 결과를 report 하지 않는 논문들도 있습니다.

3.3) Ablation study
ablation을 통해 각 element가 성능에 얼마나 영향을 끼치는지 보여줍니다.
- 여기서 [ITM vs ITM_hard(hard negative sampling for ITM)]의 결과 차이가 크지 않지만, reproduce를 통해 적은 epoch(10, 20)에서의 결과를 비교해보니, hard negative sample의 영향이 굉장히 큼을 발견했습니다. 이러한 내용은 저희의 논문을 참고하시면 확인할 수 있습니다.
3.4) Visualization
Grad-CAM(interpretation method)을 이용해 multimodal encoder의 중간 layer의 cross-attention map을 visualization 했습니다. 시각화 결과를 보면 각 단어가 뜻하는 이미지 상의 region을 잘 표시하고 있음을 볼 수 있습니다.
- Grad-CAM 외에도 저희가 직접 DINO에서 사용한 방법으로 cross-attention map을 시각화해 보았는데, 아래와 같은 word-region matching이 유의미하게 이루어짐을 볼 수 있었습니다. 단어와 region을 bounding box에 대한 정보 등을 주는 supervised 방식으로 학습하지 않았음에도 이러한 결과를 얻을 수 있다는 것이 놀라웠습니다.
더보기DINO method로 시각화



Figure 5.는 VQA task에서 질문에 대한 답을 도출할 때 이미지의 어느 영역을 많이 참고하는지를 보여줍니다.
Figure 6. 결과를 보면 단순히 Object 뿐만 아니라 attribute(blue)나 relationship(holding, next)에 대해서도 잘 인식한다는 것을 알 수 있습니다.
4) Conclusion
1. Multimodal encoder에서 image-text feature를 fusion 하기 전 pre-align 하는 새로운 framework 제안
2. Noisy web data 및 one-hot label의 한계를 개선할 수 있는 momentum distillation 제안
3. 다양한 VL downstream task에서 SOTA 달성 및 text-image alignment 시각화해 결과의 해석 가능성 보여줌관련 포스트
[코드 분석] ALBEF - Align before Fuse: Vision and Language Representation Learning with Momentum Distillation (NeurIPS 2021,
논문 리뷰를 통해 NeurIPS 2021의 spotlight 논문인 ALBEF에 대해 살펴보았습니다. 이번 포스트에서는 ALBEF 코드 중 핵심적인 부분 분석 및 Vision-Language Pretraining(VLP) 학습 경험을 공유하겠습니다. [ Pap..
cocoa-t.tistory.com
Vision-Language datasets (COCO, VG, SBU, CC3m, CC12m) 다운로드
Vision-Language datasets (COCO, VG, SBU, CC3m, CC12m) 다운로드
DALL·E 2, CLIP 등이 놀라운 결과를 보여주며 Multimodal(특히 Vision-Language) 분야에 대한 관심이 증가하고 있습니다. 주어진 텍스트를 기반으로 이미지를 생성하는 모델, 텍스트와 이미지가 공유하는 re
cocoa-t.tistory.com
728x90'Machine Learning > Multimodal Learning' 카테고리의 다른 글