-
Vision-Language datasets (COCO, VG, SBU, CC3m, CC12m) 다운로드Machine Learning/Multimodal Learning 2022. 4. 28. 01:40728x90
DALL·E 2, CLIP 등이 놀라운 결과를 보여주며 Multimodal(특히 Vision-Language) 분야에 대한 관심이 증가하고 있습니다.
주어진 텍스트를 기반으로 이미지를 생성하는 모델, 텍스트와 이미지가 공유하는 representation을 추출하는 모델 등 다양한 가능성을 보여주고 있지만, 대용량 데이터와 large-scale 모델을 사용하는 경우가 많아 리소스가 충분하지 않다면 연구가 힘든 상황입니다.
그럼에도 많은 대학원 연구실이나 스타트업에서 앞으로 멀티모달에 대한 연구 및 사업화를 구상할 것이라고 생각되기에, 비교적 데이터 사이즈는 작지만 딥러닝 학습에 도움이 될만한 양질의 dataset들을 list-up하고 다운로드 방법을 공유합니다.더보기최근 멀티모달 도메인에서 좋은 성능을 내고 있는 모델들의 공통점 중 하나는 Pre-train 과정을 거친다는 것입니다.
대용량 데이터셋에서 사전학습(Pre-training)을 통해 좋은 representation space를 형성하는 모델을 얻은 뒤 여러 downstream task에서 zero-shot 혹은 fine-tuning을 통해 뛰어난 성능을 보여줍니다. 이번 포스트는 사전학습 데이터를 위주로 소개합니다.For Pre-training

Statistics of the pre-training datasets, from ALBEF paper - COCO
- VG
- SBU
- CC3M / CC12M
For Fine-tuning ( Downstream task )
1. VQA ( Visual Question and Answer ) v2
2. NLVR2 ( Natural Language for Visual Reasoning for Real )
1) COCO : Common Objects in Context [ link ]
1. 공식 사이트에서 직접 다운 받는 방법

2. command를 이용한 방법 (사용법 등 더 자세한 설명은 이 블로그를 참고해주시기 바랍니다)
## images wget http://images.cocodataset.org/zips/train2014.zip wget http://images.cocodataset.org/zips/val2014.zip ## annotations wget http://images.cocodataset.org/annotations/annotations_trainval2014.zip
An example of COCO dataset - [ 1 image : 5 texts ]
2) VG (Visual Genome) [ link ]
공식 사이트에서 다운
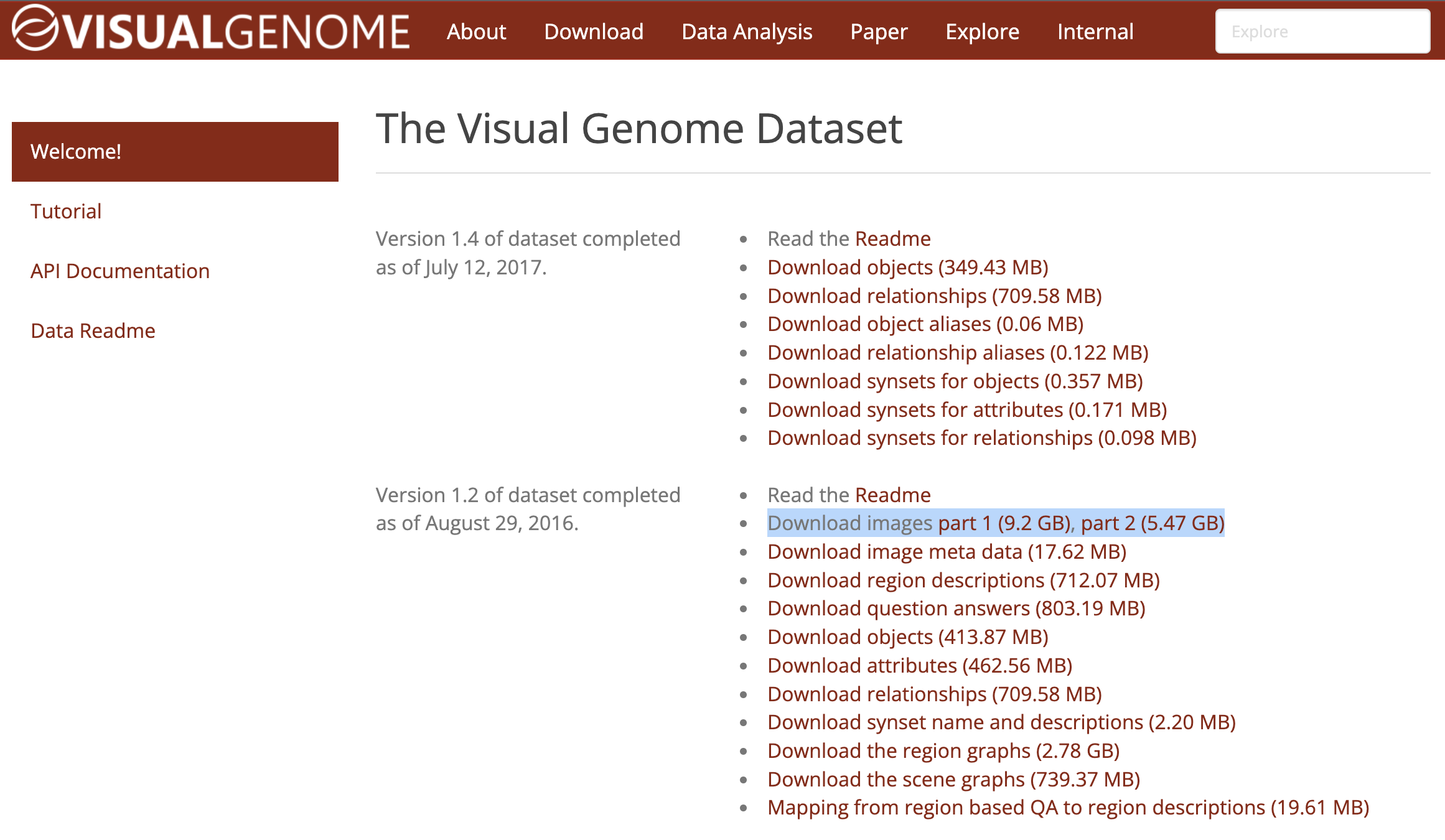
튜토리얼을 참고하시면 쉽게 데이터를 사용하실 수 있습니다
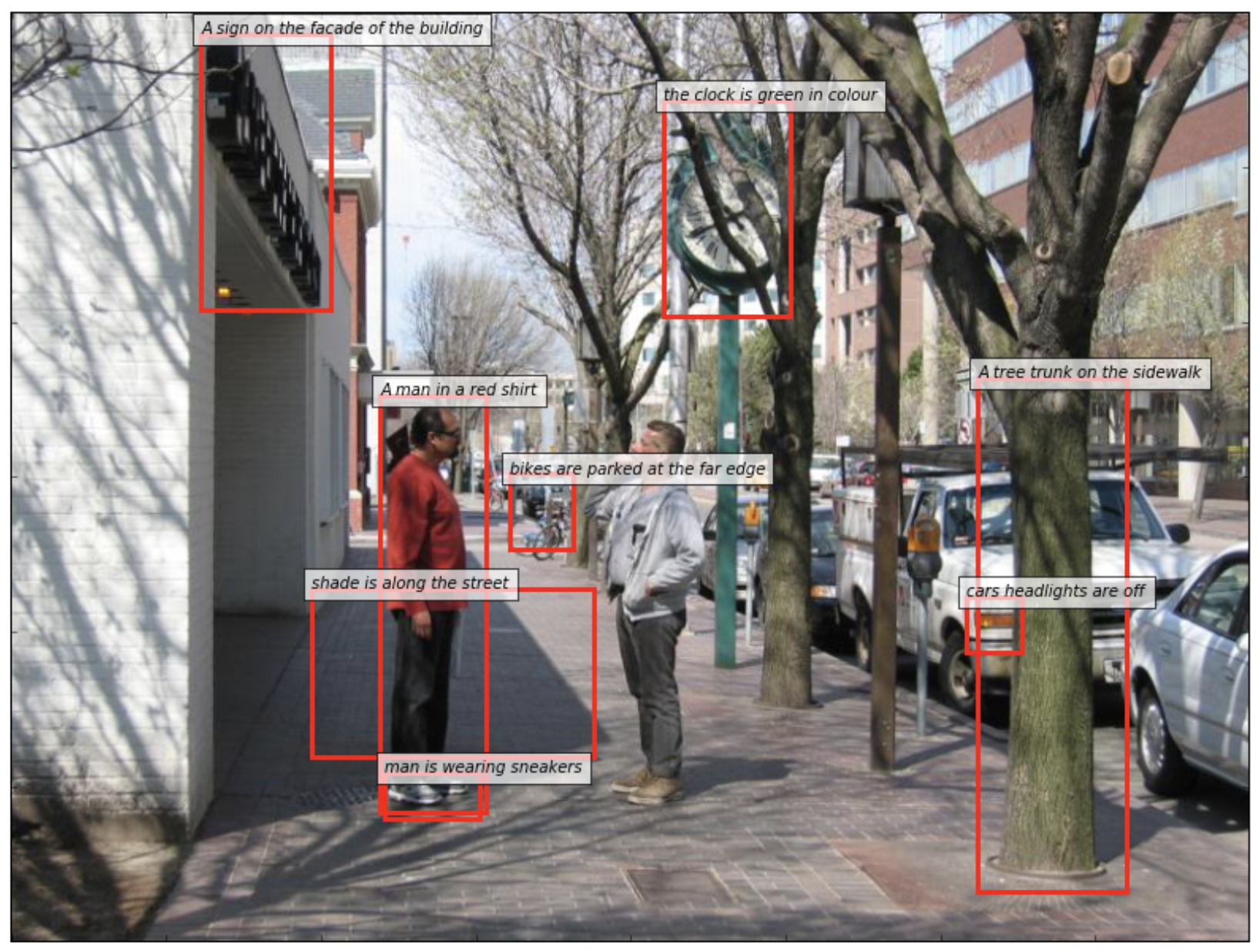
An example of visual genome dataset
3) SBU captions [ link ]
1. torchvision을 이용한 다운 [ link ]
from torchvision import datasets num_workers = 1 batch_size = 64 data_root = './sbu' dataset = datasets.SBU(root=data_root, download=True, transform=None) dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers)위 코드를 복붙해 'sbu_down.py' 파일을 만들고 실행
python sbu_down.py실행 후 아래와 같이 크롤링 출력이 나오면 잘 다운되고 있는 것입니다.

2. 공식 사이트에서 다운 (Resources → Data)

4.1) CC3M (Conceptual Captions - Google AI) [ link ]
다른 데이터셋에 비해 규모가 크고, 인터넷에 있는 데이터를 크롤링하는 과정이 필요합니다.
※ CC dataset의 경우 사이즈가 굉장히 크기 때문에 크롤링으로 이미지를 다운로드하는 데 하루 이상의 시간이 소요될 수 있습니다. 원격 서버에 다운받을 경우 tmux 혹은 screen을 이용해 원격 연결이 끊겨도 다운이 끊어지지 않게 하는 것을 추천드립니다.
- 우선 공식 사이트의 Download 창에서 크롤링할 정보가 담겨있는 tsv 파일을 다운로드합니다.

- 크롤링을 위한 코드 다운 [ github ]
git clone https://github.com/igorbrigadir/DownloadConceptualCaptions.git- 다운로드한 Train_GCC-training.tsv / Validation_GCC-1.1.0-Validation.tsv 파일을 [ DownloadConceptualCaptions ] 디렉토리로 옮긴 후 'download_data.py' 실행
cd DownloadConceptualCaptions python3 download_data.py- ModuleNotFoundError: No module named 'pandas' 에러 발생 시
ModuleNotFoundError: No module named 'pandas'pip install pandas- ModuleNotFoundError: No module named 'magic' 에러 발생 시
ModuleNotFoundError: No module named 'magic'pip install python-magic실행 후 아래와 같은 출력이 뜨면 잘 다운되고 있는 것입니다.

4.2) CC12M (Conceptual Captions - Google AI) [ link ]
위의 과정과 같지만 12 million에 달하는 pair를 다운로드하여야 하기 때문에 5일~7일 정도의 시간이 소요될 수 있습니다.
공식 사이트(github)에서 tsv 파일 다운

'download_data.py'을 cc12m.tsv 에 맞게 수정해야 합니다.
cc12m.tsv는 cc3m의 tsv 파일들과 url, caption 순서가 달라 아래와 같이 수정이 필요합니다.또한 cc12m.tsv와 download_data.py가 있는 디렉토리에 'cc12m' 이라는 디렉토리를 추가로 생성해준 뒤 아래 파일을 실행해야 합니다.
mkdir cc12mimport pandas as pd import numpy as np import requests import zlib import os import shelve import magic #pip install python-magic from multiprocessing import Pool from tqdm import tqdm headers = { #'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36', 'User-Agent':'Googlebot-Image/1.0', # Pretend to be googlebot 'X-Forwarded-For': '64.18.15.200' } def _df_split_apply(tup_arg): split_ind, subset, func = tup_arg r = subset.apply(func, axis=1) return (split_ind, r) def df_multiprocess(df, processes, chunk_size, func, dataset_name): print("Generating parts...") with shelve.open('%s_%s_%s_results.tmp' % (dataset_name, func.__name__, chunk_size)) as results: pbar = tqdm(total=len(df), position=0) # Resume: finished_chunks = set([int(k) for k in results.keys()]) pbar.desc = "Resuming" for k in results.keys(): pbar.update(len(results[str(k)][1])) pool_data = ((index, df[i:i + chunk_size], func) for index, i in enumerate(range(0, len(df), chunk_size)) if index not in finished_chunks) print(int(len(df) / chunk_size), "parts.", chunk_size, "per part.", "Using", processes, "processes") pbar.desc = "Downloading" with Pool(processes) as pool: for i, result in enumerate(pool.imap_unordered(_df_split_apply, pool_data, 2)): results[str(result[0])] = result pbar.update(len(result[1])) pbar.close() print("Finished Downloading.") return # Unique name based on url def _file_name(row): return "%s/%s_%s" % (row['folder'], row.name, (zlib.crc32(row['url'].encode('utf-8')) & 0xffffffff)) # For checking mimetypes separately without download def check_mimetype(row): if os.path.isfile(str(row['file'])): row['mimetype'] = magic.from_file(row['file'], mime=True) row['size'] = os.stat(row['file']).st_size return row # Don't download image, just check with a HEAD request, can't resume. # Can use this instead of download_image to get HTTP status codes. def check_download(row): fname = _file_name(row) try: # not all sites will support HEAD response = requests.head(row['url'], stream=False, timeout=5, allow_redirects=True, headers=headers) row['status'] = response.status_code row['headers'] = dict(response.headers) except: # log errors later, set error as 408 timeout row['status'] = 408 return row if response.ok: row['file'] = fname return row def download_image(row): fname = _file_name(row) # Skip Already downloaded, retry others later if os.path.isfile(fname): row['status'] = 200 row['file'] = fname row['mimetype'] = magic.from_file(row['file'], mime=True) row['size'] = os.stat(row['file']).st_size return row try: # use smaller timeout to skip errors, but can result in failed downloads response = requests.get(row['url'], stream=False, timeout=10, allow_redirects=True, headers=headers) row['status'] = response.status_code #row['headers'] = dict(response.headers) except Exception as e: # log errors later, set error as 408 timeout row['status'] = 408 return row if response.ok: try: with open(fname, 'wb') as out_file: # some sites respond with gzip transport encoding response.raw.decode_content = True out_file.write(response.content) row['mimetype'] = magic.from_file(fname, mime=True) row['size'] = os.stat(fname).st_size except: # This is if it times out during a download or decode row['status'] = 408 return row row['file'] = fname return row def open_tsv(fname, folder): print("Opening %s Data File..." % fname) #df = pd.read_csv(fname, sep='\t', names=["caption","url"], usecols=range(1,2)) df = pd.read_csv(fname, sep='\t', names=["url","caption"], usecols=range(0,1)) df['folder'] = folder print("Processing", len(df), " Images:") return df def df_from_shelve(chunk_size, func, dataset_name): print("Generating Dataframe from results...") with shelve.open('%s_%s_%s_results.tmp' % (dataset_name, func.__name__, chunk_size)) as results: keylist = sorted([int(k) for k in results.keys()]) df = pd.concat([results[str(k)][1] for k in keylist], sort=True) return df # number of processes in the pool can be larger than cores num_processes = 32 # chunk_size is how many images per chunk per process - changing this resets progress when restarting. images_per_part = 100 ## download_data.py 에서 cc3m을 다운받기 위한 부분을 주석 처리 ''' data_name = "validation_tmp" df = open_tsv("Validation_GCC-1.1.0-Validation.tsv", data_name) df_multiprocess(df=df, processes=num_processes, chunk_size=images_per_part, func=download_image, dataset_name=data_name) df = df_from_shelve(chunk_size=images_per_part, func=download_image, dataset_name=data_name) df.to_csv("downloaded_%s_report.tsv.gz" % data_name, compression='gzip', sep='\t', header=False, index=False) print("Saved.") data_name = "training" df = open_tsv("Train_GCC-training.tsv",data_name) df_multiprocess(df=df, processes=num_processes, chunk_size=images_per_part, func=download_image, dataset_name=data_name) df = df_from_shelve(chunk_size=images_per_part, func=download_image, dataset_name=data_name) df.to_csv("downloaded_%s_report.tsv.gz" % data_name, compression='gzip', sep='\t', header=False, index=False) print("Saved.") ''' ## cc12m을 다운받기 위한 코드 추가 data_name = "cc12m" df = open_tsv("cc12m.tsv",data_name) df_multiprocess(df=df, processes=num_processes, chunk_size=images_per_part, func=download_image, dataset_name=data_name) df = df_from_shelve(chunk_size=images_per_part, func=download_image, dataset_name=data_name) df.to_csv("downloaded_%s_report.tsv.gz" % data_name, compression='gzip', sep='\t', header=False, index=False) print("Saved.")cc12m.tsv 파일을 [ DownloadConceptualCaptions ] 디렉토리로 옮긴 후 'download_data.py' 실행
python3 download_data.py728x90'Machine Learning > Multimodal Learning' 카테고리의 다른 글