-
[코드 분석] ALBEF - Align before Fuse: Vision and Language Representation Learning with Momentum Distillation (NeurIPS 2021, Spotlight)Machine Learning/Multimodal Learning 2022. 4. 21. 19:59728x90
논문 리뷰를 통해 NeurIPS 2021의 spotlight 논문인 ALBEF에 대해 살펴보았습니다.
이번 포스트에서는 ALBEF 코드 중 핵심적인 부분 분석 및 Vision-Language Pretraining(VLP) 학습 경험을 공유하겠습니다.
[ Paper / Code ]
Outline
- ALBEF의 핵심을 담고 있는 ALBEF/models/model_pretrain.py 설명 및 분석
1) Model parameter initialization
- Image, text, multimodal encoder
- momentum model
2) Objectives
- ITC(Image-Text Contrastive learning)
- ITM(Image-Text Matching)
- MLM(Masked Language Modeling)
1) Model parameter initalization
Image encoder
ImageNet-1K에서 학습된 ViT(deit_base_patch16) 12 layer로 초기화
## Image encoder : ImageNet-1K에서 학습된 ViT(deit_base_patch16) 12 layer로 초기화 self.visual_encoder = VisionTransformer( img_size=config['image_res'], patch_size=16, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4, qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=1e-6)) if init_deit: checkpoint = torch.hub.load_state_dict_from_url( url="https://dl.fbaipublicfiles.com/deit/deit_base_patch16_224-b5f2ef4d.pth", map_location="cpu", check_hash=True) state_dict = checkpoint["model"] pos_embed_reshaped = interpolate_pos_embed(state_dict['pos_embed'], self.visual_encoder) state_dict['pos_embed'] = pos_embed_reshaped msg = self.visual_encoder.load_state_dict(state_dict,strict=False) print(msg)Text encoder & Multimodal encoder
Text encoder : BERT의 first 6 layer로 초기화
Multimodal encoder : BERT의 last 6 layer로 초기화## Text encoder : BERT의 first 6 layer로 초기화 ## Multimodal encoder : BERT의 last 6 layer로 초기화 ## 이후에 self.text_encdoer.bert(mode='text' / mode = 'fusion') 으로 구분 self.text_encoder = BertForMaskedLM.from_pretrained(text_encoder, config=bert_config) text_width = self.text_encoder.config.hidden_size ## Pre-alignment(ITC)에서 필요한 vision, text projection linear layer self.vision_proj = nn.Linear(vision_width, embed_dim) self.text_proj = nn.Linear(text_width, embed_dim) self.temp = nn.Parameter(torch.ones([]) * config['temp']) self.queue_size = config['queue_size'] self.momentum = config['momentum'] ## ITM 학습에 필요한 projection linear layer self.itm_head = nn.Linear(text_width, 2)Multimodal encoder의 경우 self-attetion 외에 cross-attention module 추가
- Self-attention module - query & key & value : textual feature
- Cross-attention module - query : textual feature / key & value : visual feature
→ 이를 활용해 DINO와 같이 특정 단어에 attention score가 높은 이미지 patch들을 visualization 하는 방법을 다른 포스트를 통해 공유하겠습니다
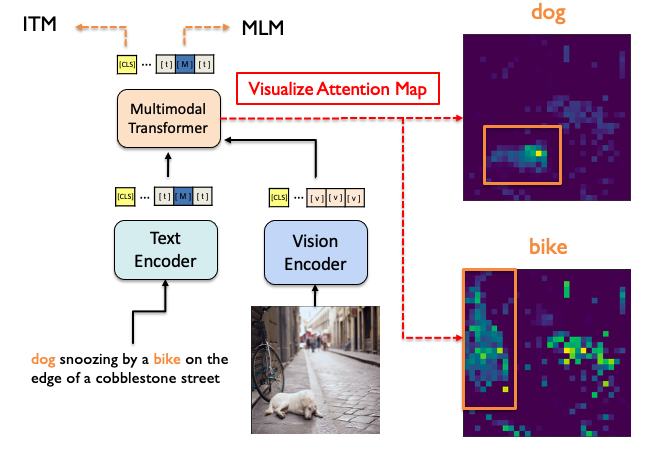
Visualize Attention Map, bounding box에 대한 정보 없이 ALBEF loss만으로 Pretrain한 모델 'dog' 에 대해 attention score가 높은 image patch들을 보면 실제 개가 있는 부분임을 확인 가능 Momentum model initialization
Momentum Distillation(MoD) 위한 model : 모두 base model과 같은 parameter로 초기화
# create momentum models self.visual_encoder_m = VisionTransformer( img_size=config['image_res'], patch_size=16, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4, qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=1e-6)) self.vision_proj_m = nn.Linear(vision_width, embed_dim) self.text_encoder_m = BertForMaskedLM.from_pretrained(text_encoder, config=bert_config) self.text_proj_m = nn.Linear(text_width, embed_dim) self.model_pairs = [[self.visual_encoder,self.visual_encoder_m], [self.vision_proj,self.vision_proj_m], [self.text_encoder,self.text_encoder_m], [self.text_proj,self.text_proj_m],] self.copy_params()
2) Objectives
2.1) ITC (Image-Text Contrasive Learning)
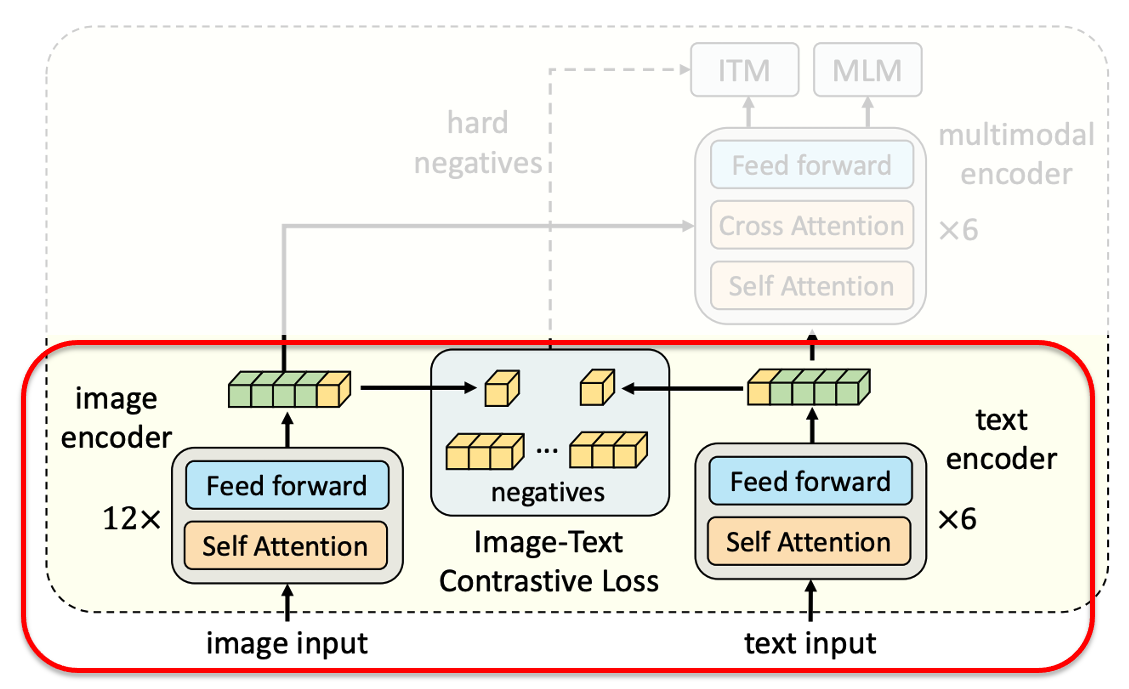
Pre-alignment part & ITC loss Forwarding pre-alingment part
image input을 visual encoder에 입력으로 준 뒤 [CLS] token의 output embedding만 linear layer 거치고,
normalize 해서 ITC 위한 image feature 추출text input도 text encoder를 거쳐 위와 같은 과정을 통해 [CLS] token으로 text feature 추출
def forward(self, image, text, alpha=0): with torch.no_grad(): self.temp.clamp_(0.001,0.5) image_embeds = self.visual_encoder(image) image_atts = torch.ones(image_embeds.size()[:-1], dtype=torch.long).to(image.device) ## image를 visual encoder에 입력으로 준 뒤 [CLS] token만 linear layer를 거치고, ## normalize 해서 ITC 위한 image feature 추출 ## image_embeds[:,0,:] : batch 내 이미지들의 [CLS] 토큰 embedding image_feat = F.normalize(self.vision_proj(image_embeds[:,0,:]),dim=-1) ## mode='text' 이므로 text encoder / mode='fusion'일 경우 multimodal encoder text_output = self.text_encoder.bert(text.input_ids, attention_mask = text.attention_mask, return_dict = True, mode = 'text') text_embeds = text_output.last_hidden_state text_feat = F.normalize(self.text_proj(text_embeds[:,0,:]),dim=-1)Contrastive loss
1. queue를 이용해 현재 및 이전 batch 내에 있던 momentum image, text feature를 저장
2. 현재 batch 내의 feature와 queue에 있는 feature 이용해 similarity matrix 생성 (@ 연산자 : 행렬곱)
3. momentum model로 얻은 [sim_i2t_m], [sim_t2i_m] 이 pseudo-target 이 됨 (i2t : image to text)
- 각 행을 sum 하면 1이 되게끔 해줌(image-text 사이의 similarity 높을수록 1에 가까운 값이 됨)4. sim matrix와 같은 size의 행렬 생성한 뒤, positive pair에 해당하는 diagonal term은 1로,
나머지 off-diagonal term은 negative pair 이므로 0으로 만들어 ground truth label 생성5. pseudo-target과 ground truth label을 convex combination 해서 최종 target으로 생성
결과적으로 positive pair는 embedding space 에서 가까워지게, negative pair는 멀어지게 학습하면서
momentum distillation 으로 image-text 사이의 유사도 반영하여 학습 (hyper-parameter α로 조절)
# get momentum features with torch.no_grad(): self._momentum_update() image_embeds_m = self.visual_encoder_m(image) image_feat_m = F.normalize(self.vision_proj_m(image_embeds_m[:,0,:]),dim=-1) ## queue를 이용해 현재 및 이전 batch 내에 있던 momentum image feature 저장 image_feat_all = torch.cat([image_feat_m.t(),self.image_queue.clone().detach()],dim=1) text_output_m = self.text_encoder_m.bert(text.input_ids, attention_mask = text.attention_mask, return_dict = True, mode = 'text') text_feat_m = F.normalize(self.text_proj_m(text_output_m.last_hidden_state[:,0,:]),dim=-1) ## queue를 이용해 현재 및 이전 batch 내에 있던 momentum image feature 저장 text_feat_all = torch.cat([text_feat_m.t(), self.text_queue.clone().detach()],dim=1) ## similarity matrix의 pseudo-target 생성 위한 momentum sim matrix sim_i2t_m = image_feat_m @ text_feat_all / self.temp sim_t2i_m = text_feat_m @ image_feat_all / self.temp ## label 생성 : negative 는 0으로 positive pair는 1로 sim_targets = torch.zeros(sim_i2t_m.size()).to(image.device) sim_targets.fill_diagonal_(1) ## diagonal term은 positive pair 이므로 1로 sim_i2t_targets = alpha * F.softmax(sim_i2t_m, dim=1) + (1 - alpha) * sim_targets sim_t2i_targets = alpha * F.softmax(sim_t2i_m, dim=1) + (1 - alpha) * sim_targets sim_i2t = image_feat @ text_feat_all / self.temp sim_t2i = text_feat @ image_feat_all / self.temp loss_i2t = -torch.sum(F.log_softmax(sim_i2t, dim=1)*sim_i2t_targets,dim=1).mean() loss_t2i = -torch.sum(F.log_softmax(sim_t2i, dim=1)*sim_t2i_targets,dim=1).mean() loss_ita = (loss_i2t+loss_t2i)/2 self._dequeue_and_enqueue(image_feat_m, text_feat_m)2.2) ITM (Image-Text Matching)
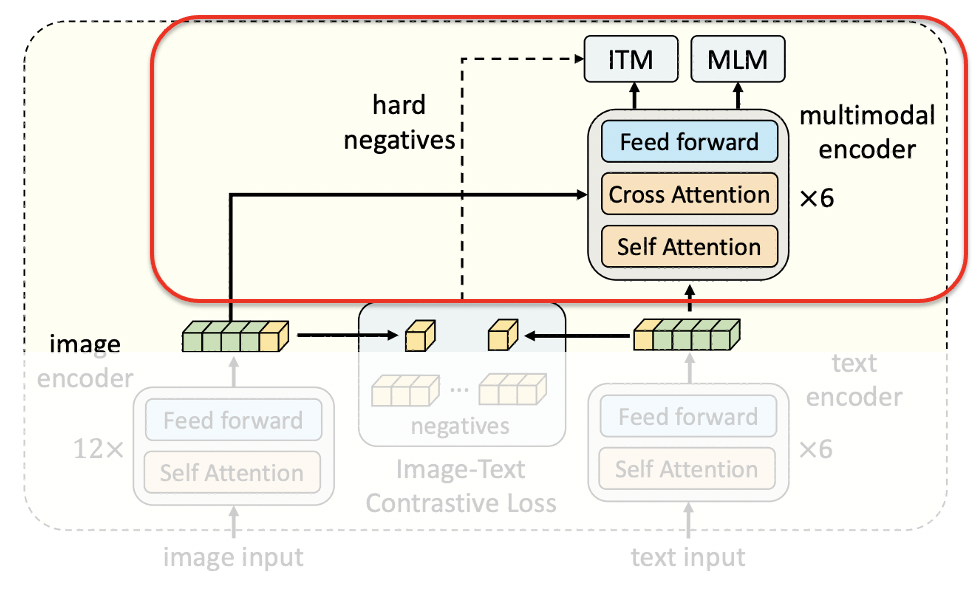
ITM & MLM Positive image-text pair
ITC 과정에서 unimodal encoder를 거쳐 생성된 image embedding과 text embedding을
multimodal encoder의 input으로 전달 (mode = 'fusion' / 우선 positive pair에 대해서만)이때 self-attention의 q,k,v는 text embedding으로,
cross-attention에서 k,v는 image embedding으로, q는 text embedding으로 계산# forward the positve image-text pair output_pos = self.text_encoder.bert(encoder_embeds = text_embeds, attention_mask = text.attention_mask, encoder_hidden_states = image_embeds, encoder_attention_mask = image_atts, return_dict = True, mode = 'fusion', )Select hard negative image-text pair
weights_i2t, weights_t2i는 hard negative sample을 뽑기 위한 matrix 생성
- sim_matrix 중 queue를 이용해 얻은 부분 외에 batch size만큼만 자른 뒤
- 각 행을 기준으로 softmax를 취해줘 합이 1이 되게끔 만들어줌
- i2t의 경우 각 행은 image 하나에 대해 batch 내 text들의 유사도를 나타냄
- diagnoal term은 positive pair로 0을 넣어줘 negative 값만 남겨둠
Select a negative image for each text (vice versa)
- multinomial을 하면 weighted sampling을 할 수 있음
- 위에서 batch 내 negative pair들 사이의 유사도를 구했고,
이를 이용해 가장 유사도가 높은 negative sample을 뽑음(hard negative sampling)
각 image에 대한 negative text를 하나씩 뽑고, 각 text에 대한 negative image를 하나씩 뽑아
image-text negative pair에 대한 feature들을 multimodal encoder에 넣어줌## weights_i2t, weights_t2i는 hard negative sample을 뽑기 위한 matrix ## sim_matrix 중 queue를 이용해 얻은 부분 외에 batch size만큼만 자른 뒤 ## 각 행을 기준으로 softmax를 취해줘 합이 1이 되게끔 만들어줌 ## i2t의 경우 각 행은 image 하나에 대해 batch 내 text들의 유사도를 나타냄 ## diagnoal term은 positive pair로 0을 넣어줘 negative 값만 남겨둠 with torch.no_grad(): bs = image.size(0) weights_i2t = F.softmax(sim_i2t[:,:bs],dim=1) weights_t2i = F.softmax(sim_t2i[:,:bs],dim=1) weights_i2t.fill_diagonal_(0) weights_t2i.fill_diagonal_(0) # select a negative image for each text ## multinomial을 하면 weighted sampling을 할 수 있음 ## 위에서 batch 내 negative pair들 사이의 유사도를 구했고, ## 이를 이용해 가장 유사도가 높은 negative sample을 뽑음(hard negative sampling) image_embeds_neg = [] for b in range(bs): neg_idx = torch.multinomial(weights_t2i[b], 1).item() image_embeds_neg.append(image_embeds[neg_idx]) image_embeds_neg = torch.stack(image_embeds_neg,dim=0) # select a negative text for each image text_embeds_neg = [] text_atts_neg = [] for b in range(bs): neg_idx = torch.multinomial(weights_i2t[b], 1).item() text_embeds_neg.append(text_embeds[neg_idx]) text_atts_neg.append(text.attention_mask[neg_idx]) text_embeds_neg = torch.stack(text_embeds_neg,dim=0) text_atts_neg = torch.stack(text_atts_neg,dim=0) text_embeds_all = torch.cat([text_embeds, text_embeds_neg],dim=0) text_atts_all = torch.cat([text.attention_mask, text_atts_neg],dim=0) image_embeds_all = torch.cat([image_embeds_neg,image_embeds],dim=0) image_atts_all = torch.cat([image_atts,image_atts],dim=0) ## 각 image에 대한 negative text를 하나씩 뽑고 ## 각 text에 대한 negative image를 하나씩 뽑아 ## image-text negative pair에 대한 feature들을 multimodal encoder에 넣어줌 output_neg = self.text_encoder.bert(encoder_embeds = text_embeds_all, attention_mask = text_atts_all, encoder_hidden_states = image_embeds_all, encoder_attention_mask = image_atts_all, return_dict = True, mode = 'fusion', )ITM loss
multimodal encoder를 거친 최종 output의 [CLS] 토큰만 모아 vl_embeddings 생성
itm_head (linear layer) 거쳐 label(positive : 1 / negative : 0)로 cross entropy 계산vl_embeddings = torch.cat([output_pos.last_hidden_state[:,0,:], output_neg.last_hidden_state[:,0,:]],dim=0) vl_output = self.itm_head(vl_embeddings) itm_labels = torch.cat([torch.ones(bs,dtype=torch.long), torch.zeros(2*bs,dtype=torch.long)], dim=0).to(image.device) loss_itm = F.cross_entropy(vl_output, itm_labels)2.3) MLM (Masked Language Modeling)
Masking
- 문장 내 각 단어를 15% 확률로 masking
##================= MLM ========================## input_ids = text.input_ids.clone() labels = input_ids.clone() probability_matrix = torch.full(labels.shape, self.mlm_probability) input_ids, labels = self.mask(input_ids, self.text_encoder.config.vocab_size, image.device, targets=labels, probability_matrix = probability_matrix)Momentum distillation
- momentum model로 [MASK]에 들어갈 수 있는 pseudo-target 생성

with torch.no_grad(): logits_m = self.text_encoder_m(input_ids, attention_mask = text.attention_mask, encoder_hidden_states = image_embeds_m, encoder_attention_mask = image_atts, return_dict = True, return_logits = True, )MLM loss
- 단어의 true label과 momentum distillation으로 얻은 soft label로 output logit과의 cross entropy 계산
- 주의 : ITC, ITM 계산할 때의 text input과 다르므로 (masked input)
text encoder와 multimodal encoder에 추가적인 forwarding 필요 (image encoder는 추가 x)
mlm_output = self.text_encoder(input_ids, attention_mask = text.attention_mask, encoder_hidden_states = image_embeds, encoder_attention_mask = image_atts, return_dict = True, labels = labels, soft_labels = F.softmax(logits_m,dim=-1), alpha = alpha ) loss_mlm = mlm_output.loss
Conclusion
위에서 설명한 과정으로 Pre-train을 진행하고, 각 downstream task에 맞게 모델 수정 및 fine-tune을 합니다.
그 결과 당시 SOTA를 달성했으며, 이후에 X-VLM, BLIP 등 ALBEF를 base로 한 VLP 논문들이 나왔습니다.다양한 VLP framework(CLIP, SimVLM, ViLT 등) 중 한 축이 될 것으로 보이며,
코드 또한 이해 및 변형이 쉽게 되어있어 앞으로 더 많은 추가 연구가 있을 것으로 기대됩니다.728x90'Machine Learning > Multimodal Learning' 카테고리의 다른 글