-
[논문 리뷰] 🦩 Flamingo: a Visual Language Model for Few-Shot Learning - 1. 핵심 특징 및 예제 설명Machine Learning/Multimodal Learning 2022. 5. 4. 03:49728x90
구글 딥마인드에서 발표한 Visual Language Model로, 이미지와 텍스트로 구성된 input을 받아 텍스트 output을 생성합니다.
다양한 Vision-Language task에서 적은 수의 example로 학습해 fine-tuned model의 SotA에 가까운 성능을 보입니다.
정량적인 결과 외에도 흥미로운 예제들이 많기 때문에 이를 천천히 살펴보고, 실제 어떤 서비스에 적용 가능할지 고민해봅니다.
또한 Flamingo가 새롭게 제안한 구조와 method에 대해서도 관련 연구와 함께 살펴봅니다.
[ paper | blog ]Abstract
🦩Flamingo : 소수의 예제(few-shot)로 다양한 task를 빠르게 적응 및 수행할 수 있는 Visual Language Model
구조적 특징1. 사전 학습한 모델들을 활용해 해당 모델들이 갖고 있는 이점을 활용합니다.
2. 정해진 순서가 아닌 임의의 순서로 나열된 이미지, 텍스트 시퀀스를 처리할 수 있습니다.
3. 이미지 뿐만 아니라 영상 또한 입력으로 받아 원활하게 소화합니다.위와 같은 특징 덕분에 임의로 교차 배치된 텍스트와 이미지로 이루어진 대규모 멀티모달 웹 데이터로 학습이 가능합니다. 또한 이러한 대용량 데이터로부터 이미지와 텍스트의 일반적인 특징을 학습해 다양한 멀티모달(텍스트와 이미지, 혹은 비디오) 벤치마크에서 적은 수의 예제만으로도 좋은 성능을 보여줍니다.
1) Flamingo 예제를 먼저 살펴보면
input prompt로 어떤 예제를 넣어주었는지와 그 예제들을 바탕으로 완성한 문장이 어떤 것인지 보여줍니다. 몇 개의 예제만 보고(few-shot) 그 예제의 형식에 맞춰 문장을 완성한 것을 볼 수 있습니다. (예제를 하나하나 곱씹어 보면 단순히 이미지를 잘 분류하거나 문장을 그럴듯하게 완성하는 것이 아니라, 정말로 세상을 이해하고 있는 듯한 느낌을 줍니다. 이미지와 문장 속에 있는 객체, 관계, 속성 등에 대한 이해를 바탕으로 답을 도출한 것을 확인할 수 있습니다.) 잊지 말아야 할 점은 하나의 모델로 다양한 task에서 few-shot 했을 때의 결과라는 것입니다.
이미지, 비디오 Understanding Tasks
1. [ '동물 이미지' + '동물 이름. 해당 동물에 대한 설명' ]

동물의 이미지를 보고 단순히 어떤 종인지 분류하는 것을 넘어서 이미지로 알 수 없는 동물의 특징까지 이해합니다.
2. [ '미술작품 이미지' + '작품 관련 질문' + 'Answer : ' + '답변' ]

명화를 보고 해당 그림이 그려진 도시를 맞춥니다.
3. [ '표지판 이미지' + 'Output : ' + '표지판 속 글자' ]

이미지 속 글자를 읽을 수 있습니다.
4. [ '계산식 이미지' + '계산식 글자, 계산식의 답' ]

이미지 속 글자를 읽는 것을 넘어 '수학 계산'을 수행합니다.
5. [ 'DALL·E 2로 만든 이미지' + 'Output' + '이미지 설명' ]

학습한 web corpora dataset에 없던 생성된 이미지를 보고 납득할 만한 caption을 생성합니다.
6. [ '이미지' + '프랑스어 설명' ]

영어뿐만 아니라 프랑스어로 문장 이해 및 생성 가능합니다.
7. [ '동물 이미지' + '동물 이름 : 수' ]

이미지 속 객체들을 분리하여 파악하고 그 수를 셀 수 있습니다.
8. [ '문장' + '이미지' + '문장' + '이미지' + '문장' ] → [ '문장' ]

'이미지 + 문장'과 같이 정해진 입력 형식이 아닌 다른 순서의 입력도 처리 가능합니다.
( 'Dreams from my Father' - 오바마 전 대통령의 자서전 )9. [ '비디오' + '질문' ] → [ '답변' ]

비디오와 질문을 input으로 받아 이에 대한 답변 생성
Visual dialogue - 이미지를 참고한 대화
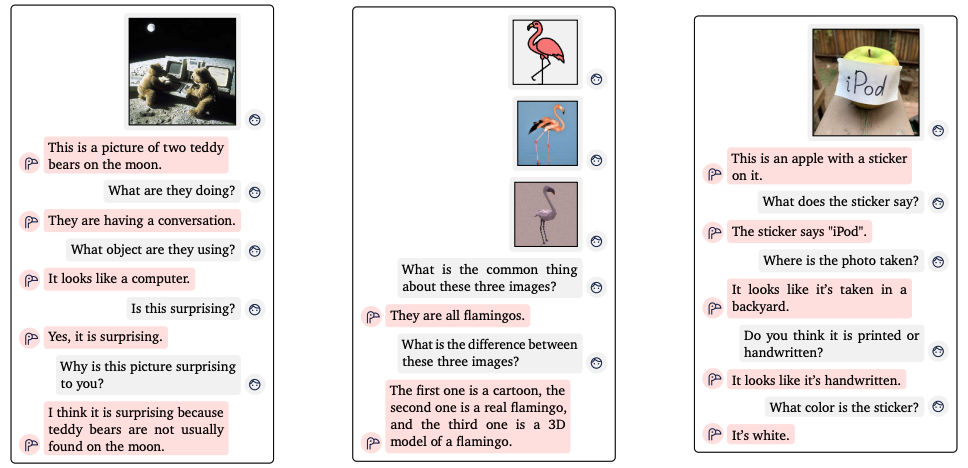
가장 왼쪽 대화의 마지막 부분을 보면, 이 사진이 왜 놀랍냐는 질문에 'teddy bears는 보통 달에서 발견할 수 없기 때문'이라고 답합니다. teddy bear와 달의 일반적인 특징과 감정인 'surprising'의 의미도 이해해야 가능한 답변입니다.
두 번째 대화에서는 플라밍고를 다른 스타일(cartoon, real image, 3D)로 표현한 것을 구분했습니다.
세 번째 대화에서 이미지에 대한 디테일한 질문들도 잘 답합니다.
제일 왼쪽 대화를 보면, 이미지를 보고 '강아지가 소파를 망가뜨린 것 같다', '사람이 화난 것 같다'는 추측을 합니다.
제일 오른쪽 대화를 보면, 볼을 숨기고 싶다고 하자 주변에 있는 천을 이용해 숨길 수 있다고 답합니다.
AI 비서 혹은 시각장애인을 위한 보조 디바이스 등 우리 주변에 AI가 스며들 수 있는 가능성을 보여주는 것 같습니다.
Selected single image samples

가운데 그림을 보면, 어떤 부분이 이상한지 그리고 그 이유까지 잘 설명하고 있습니다.
오른쪽 그림에서도 답변에 대한 이유를 이미지에서 잘 찾아 설명합니다.

가운데 결과를 보면, 이미지에 모기가 없고 질문에도 모기에 대한 언급이 없지만 모기장을 파악해 그 역할을 설명합니다.

사람에게는 질문을 이해하고 이미지를 참고해 적절한 답과 그 근거를 도출하는 것이 쉬운 일이지만, 이는 상식을 요구하는 문제라는 걸 생각해보면 모델이 위의 예들과 같은 결과를 내놓는 것이 당연하지 않다는 걸 느끼게 됩니다.
Selected video samples

비디오에서 1FPS로 샘플링된 frame들과 질문을 input promt로 넣어줬을 때 Flamingo는 그에 대한 답을 생성합니다. 영상에서 어떤 객체가 있고, 어떤 일이 일어나고 있는지(체중계로 닥스훈트의 무게를 재는 것, 게임 속 아바타가 잡은 것이 검이라는 것) 파악하고, 한 frame에 나오지 않더라도 이를 인지(각각 따로 나오는 펜, 가위, 고무줄을 식별, 따로 나오는 글자를 식별) 합니다.
2) 기존 Fine-tuned SotA 와의 비교

Performance relative to Fine-Tuned SotA 그림에서 점선(100% 위)은 기존 fine-tuned 모델 중 SotA 결과를 100%에 해당하는 기준으로 설정한다는 것을 뜻합니다. 이때 빨간색 바는 Flamingo를 각 task에서 32개의 예제만 보고 test를 진행했을 때 기존 SotA 대비 어느정도의 성능인지 보여줍니다.
왼쪽 결과를 살펴보면, 16개 중 6개 task에서 outperform 한 것을 확인할 수 있고, 기존 zero/few-shot 결과와 비교했을 때 꽤나 큰 차이로 향상된 성능을 보여줍니다.
가운데 결과는 모델의 파라미터는 80B으로 유지하고, few-shot의 수를 바꿔가며 결과를 report 했습니다. 8 shots 만으로도 좋은 성능을 보이고 zero-shot도 나쁘지 않은 결과를 보입니다.
오른쪽 결과는 32 shots은 유지하고 모델의 파라미터 수를 바꿨을 때의 결과입니다. 모델이 커질수록 결과가 좋아집니다.
+ 하나의 모델로 few shot learning해 여러 task에서 좋은 성능을 보인다는 점은 놀랍지만, Flamingo를 사전학습할 때 굉장히 큰 dataset에서 학습하고, 모델의 사이즈가 기존 SotA 모델들보다 훨씬 크다는 걸 감안했을 때 위와 같이 비교하는 것이 정말 fair 한지는 잘 모르겠습니다. 이러한 머니게임을 비판하는 시각도 적지 않습니다.
3) Approach
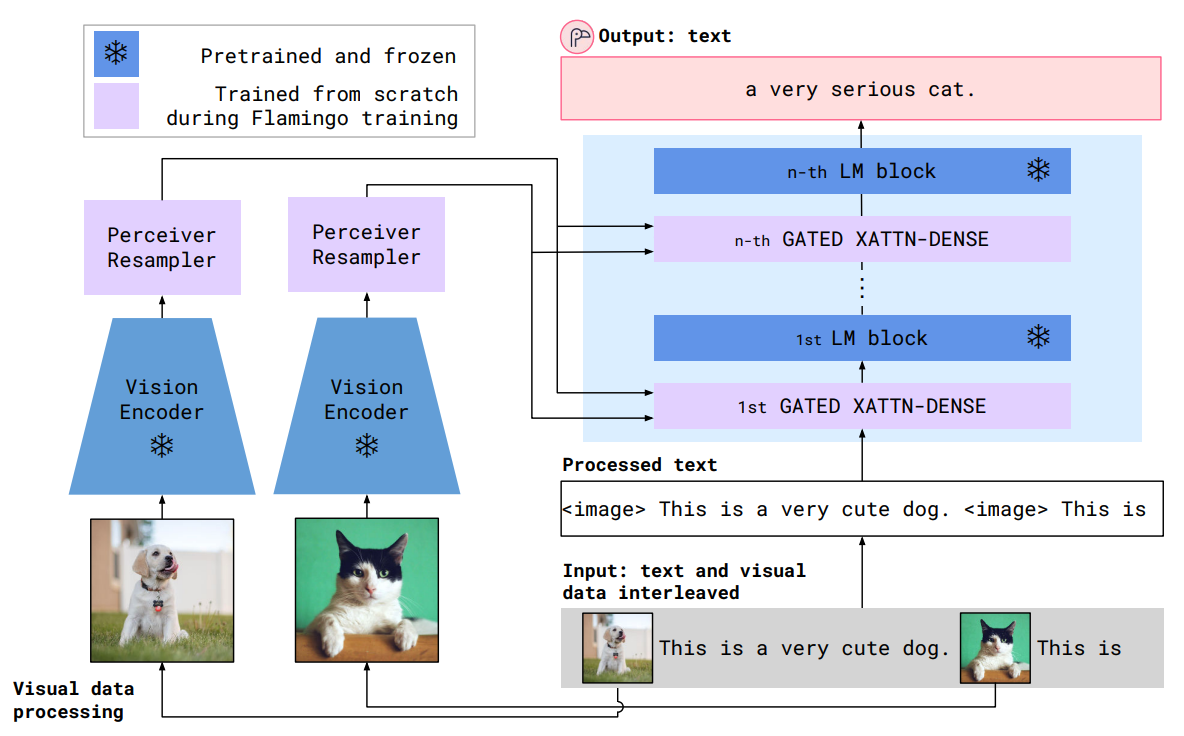
Overview of the Flamingo model 1. 사전 학습한(pretrained) 모델을 활용 - 그림에서 frozen으로 표시된 부분
Vision side
- CLIP과 같이 text-image contrastive learning으로 vision encoder(NFNet)를 사전학습한 후, Flamingo framework 안에서는 추가적인 학습을 하지 않습니다. 이러한 contrastive learning을 통해 vision encoder는 객체의 color, shape, nature, position 등 시각적 특징을 표현하는 semantic spatial feature를 추출할 수 있게 됩니다.
Language side
- large and diverse text corpus로 학습된 autoregressive language model(LM, Chinchilla)을 사용합니다. 이처럼 사전학습한 모델을 가져와 기존 모델이 갖고 있던 강력한 언어 생성 능력을 얻고, LM weights에 저장된 수많은 양의 knowledge를 사용할 수 있게 됩니다.
각 uni-modal side의 장점을 유지하기 위해 freeze(추가로 학습하지 않음) 했다는 것을 잊지 말아야 합니다.
2. 두 개의 학습 가능한 components를 통해 vision-language side를 연결
Perceiver Resampler
- Vision encoder로부터 얻은 다양한 사이즈를 갖는 spatio-temporal features를 고정된 작은 사이즈(64 시퀀스)의 visual tokens으로 mapping하는 역할을 합니다. (그렇기 때문에 resampler라는 이름을 갖습니다.) 이처럼 출력 사이즈를 줄여 vision-text cross attention의 계산량을 줄 일 수 있고, 특히 여러 개의 긴 비디오를 처리할 때 이러한 과정은 큰 이점으로 작용합니다.
Gated Cross Attention layers
- Attention의 key, value를 vision feature로부터 얻고, query로 language feature를 사용해 scratch부터 학습합니다. 이 layer에서는 시각적 정보와 언어적 정보를 통합해 LM이 다음 토큰을 예측하는 task를 수행하는 데 도움을 줍니다.
(각 component 및 전체 흐름의 구체적인 설명은 다음 포스트에서 계속)
4) 물론 아직 개선해야 할 부분도 많이 남아있습니다
Limitations, failure cases
사전학습한 언어 모델(pretrained language model)을 freeze 해서 사용하기 때문에 이 모델의 단점 또한 그대로 유지됩니다. 예를 들어 causal(or autoregressive) modeling은 conditioning input에 대해 BERT와 같은 bidirectional modeling 보다 less expressive 합니다. 또한 transformer-based language model의 경우 학습할 때의 input sequence 보다 매우 긴 test sequence가 들어오면 성능이 떨어집니다. 뿐만 아니라 아래 그림과 같이 사진을 제대로 반영 못하거나 근거 없는 추측을 하는 경우도 발생합니다.

Risks
Captioning 등 여러 task를 이미지와 함께 수행할 때 gender와 racial biases 문제가 발생할 수 있습니다. 이러한 biases에 대한 주의 혹은 해결 없이 배포하면 많은 문제를 야기할 수 있습니다. 이러한 문제를 방지하고 measure 하기 위한 연구도 진행되고 있으며 논문에서는 Flamingo의 Bias evaluation 결과도 report 하고 있습니다.
+ Pretrain 과정에서 엄청난 cost가 들어가고, 기존 모델들에 비해 큰 모델을 사용한다는 점도 개선이 필요한 부분이라고 생각합니다. 실제 서비스에 적용하기 위해 경량화, 효율적인 사전학습 방법 등도 많은 연구가 필요해 보입니다.
5) Conclusion
- 구글 딥마인드가 최근(2022.04.28)에 공개한 VLM(🦩 Flamingo)의 간략한 소개와 논문 속 다양한 예제를 살펴보았습니다.
- 물론 cherry-pick 결과일 수 있지만, Visual Language Model의 가능성과 잠재성을 충분히 보여주었다고 생각합니다.
- 우리 생활 속 다양한 문제와 불편함을 해결하는 데 어떻게 활용할 수 있을지 고민해보면 좋을 것 같습니다.
728x90'Machine Learning > Multimodal Learning' 카테고리의 다른 글