-
[논문 리뷰] GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion ModelsMachine Learning/Multimodal Learning 2022. 5. 17. 04:07728x90
DALL-E 2의 기본 구조가 되었던 GLIDE 논문을 리뷰합니다. OpenAI에서 발표한 Text-to-Image 모델이며,
기존 GAN이 주축이던 Text-to-Image domain에 DIffusion model을 도입해 사실적인 이미지를 생성했습니다.
또한 in-painting을 활용한 이미지 editing으로 복잡하고 긴 텍스트도 이미지에 반영할 수 있는 방법을 제안합니다.
GLIDE의 경우 코드와 작은 사이즈의 모델 파라미터도 공개되어 있어, 코랩을 활용한 데모도 소개하겠습니다.(다음 포스트에서)
[ paper | code ]
GLIDE의 Text-conditional image inpainting 예시.
(Guided Language to Image Diffusion for Generation and Editiong)
1. Introduction
Text-to-Image
최근 자유로운 형식(free-form)의 텍스트 prompt를 인풋으로 받아 관련된 이미지를 생성하는 text-conditional image model들이 제안되었습니다. 하지만 아직은 텍스트의 정보를 온전히 반영한 사실적인(photorealistic) 이미지를 생성하지는 못하고 있습니다.

기존 text-to-image method로 생성된 이미지들, from [ Cross-Modal Contrastive Learning for Text-to-Image Generation ] Diffusion models
Diffusion model은 최근 고화질 이미지를 생성해내는 Generative model로 많은 관심을 받고 있습니다. 특히 [ Diffusion Models Beat GANs on Image Synthesis ] 논문은 classifier guidence & upsampling을 활용해 Diffusion model로 고해상도 이미지를 생성하고, 당시 기준 SotA GAN 보다 FID score에서 좋은 성능을 보였습니다. (여기서 classifier guidence는 Diffusion model을 학습할 때 분류기(classifier)의 gradient를 활용하는 것으로 자세한 내용은 Diffusion model 포스트를 통해 다루겠습니다.)
또한 [ Classifier-free diffusion guidance ]에서는 추가적인 이미지 분류기의 학습을 필요로 하는 Classifier-guided diffusion model을 지적하며 생성 모델만으로 이미지를 생성하는 classifier-free guidance 방법을 제안했습니다.

[ Diffusion Models Beat GANs on Image Synthesis ] 논문에 소개된 Diffusion model로 합성된 이미지
Text-Guided Diffusion Models
저자들은 텍스트를 반영하며 사실적인 이미지를 생성하는 모델을 만들기 위해 'guided diffusion model'을 Text-to-Image domain에 적용했습니다. 실제 사람들에게 DALL-E 1으로 만든 이미지와 GLIDE가 만든 이미지를 비교하는 설문을 실시했을 때, GLIDE 이미지의 photorealism 선호도가 87% 더 높았고, 캡션과의 유사도(caption similarity)는 69% 높았습니다.

“A cozy living room with a painting of a corgi on the wall above a couch and a round coffee table in front of a couch and a vase of flowers on a coffee table”.
위 prompt에 대해 DALL-E 1과 GLIDE가 생성해 낸 이미지들(random sampling)
GLIDE가 생성해낸 이미지들(selected).
다양한 스타일의 이미지를 생성할 수 있으며, 첫 번째 사진을 보면 텍스트에는 설명되어 있지 않은 물에 건물이 비친 모습도 반영된 것을 알 수 있습니다. 또한 제일 마지막 사진은 빌딩에 대한 언급이 없음에도 뉴욕 빌딩 사진을 생성했습니다. 이처럼 GLIDE는 world knowledge를 반영해 이미지를 생성할 수 있습니다.
(우리의 text2image에 대한 기준이 이미 높아져 이러한 그림을 그리는 것이 당연스럽게 느껴질 수 있지만, 그림 하나하나를 곱씹어 보면 당연한 결과가 아님을 알 수 있습니다.)Edit images with inpainting
GLIDE 실험 결과, 복잡한 prompt에 대해서는 사실적인 이미지를 만들어내기 힘들었습니다. 이를 개선하기 위해 복잡한 prompt에 대해 순차적으로 이미지를 개선해 나가는 editing 방법을 제안합니다. 이를 위해 이미지 내 손상된 부분 혹은 지워진 부분을 복구하는 이미지 inpainting method를 적용했습니다. 그 결과, 캡션을 기반으로 이미지를 editing 했을 때 물체의 그림자를 표현하고, 유리나 물에 반사된 물체의 모습도 표현하는 등 더욱더 사실적인 이미지를 만들 수 있었습니다.

순차적으로 이미지를 개선해 원하는 이미지 생성합니다. 다양한 서비스에 적용 가능할 것으로 보입니다.

원본 이미지의 스타일을 반영해 이미지가 수정되는 것을 확인할 수 있습니다.
2. Background
2.1. Diffusion Models
이번 포스트에서는 GLIDE에 나와있는 수준으로 diffusion models을 살펴보고,
추후 다른 포스트에서 diffusion models을 관련 논문과 함께 자세히 다루겠습니다.
(큰 틀을 이해하는 데 무리는 없을 것으로 보입니다.)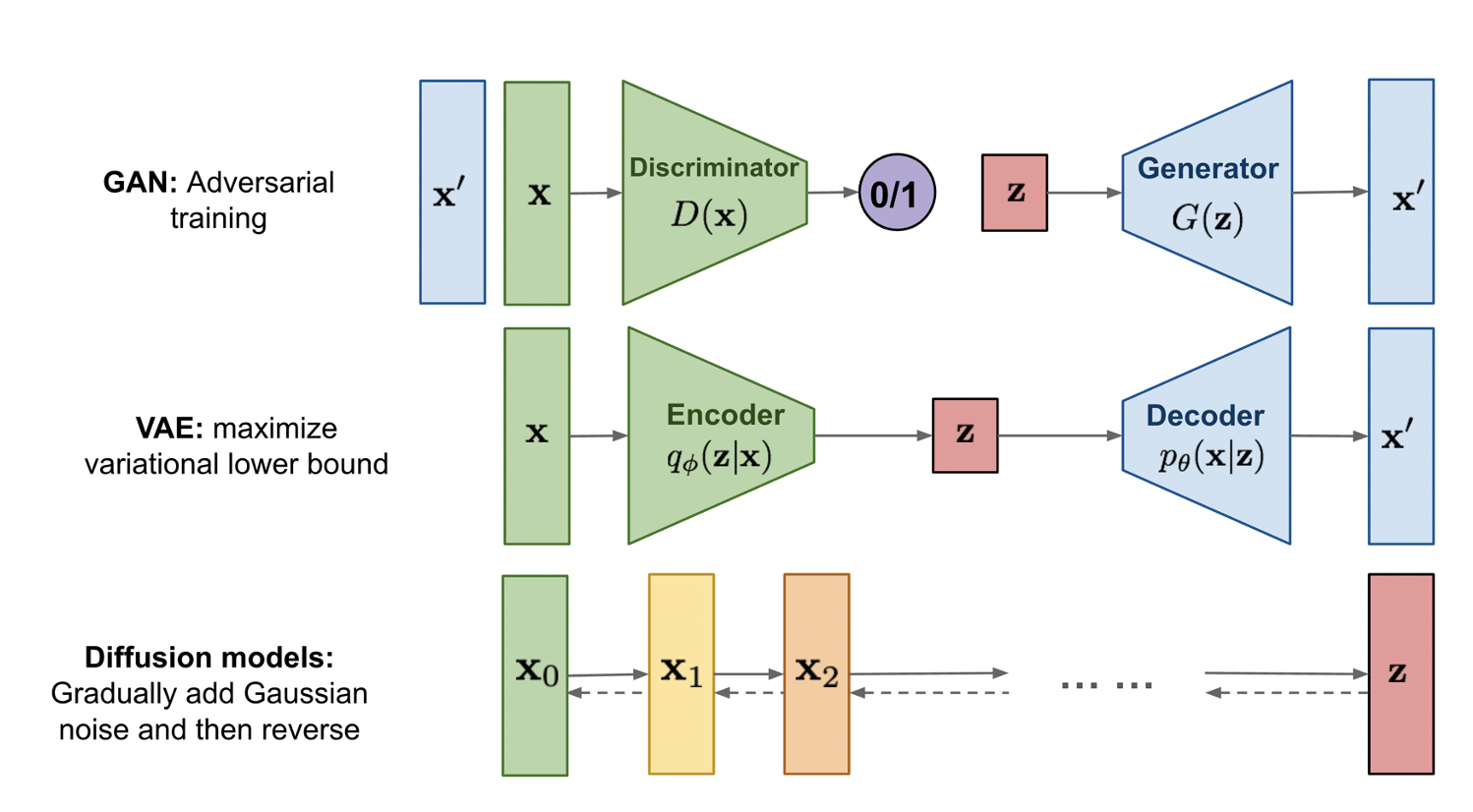
출처 : https://lilianweng.github.io/posts/2021-07-11-diffusion-models/ Diffusion model은 유명한 생성 모델인 VAE나 GAN과는 다르게, 원본 이미지와 같은 차원을 가지는 고차원 latent variable을 이용해 학습을 진행합니다. 이런 고차원 latent variable을 활용할 수 있는 이유는 diffusion process를 통해 학습이 진행되기 때문인데, diffusion process를 이해하기 위해서는 우선 마르코프 체인(Markov chain)을 알아야 합니다.
마르코프 체인 설명을 위해 두 가지 핵심을 먼저 소개합니다. 첫 번째로, 마르코프 특성(Markov property)은 과거 상태들과 현재 상태가 주어졌을 때, 미래 상태는 현재 상태에 의해서만 결정(과거 상태와는 독립적)되는 것을 뜻합니다. 두 번째 핵심은 이산 시간(discret time)으로, 어떤 상태가 변화할 때 연속적이지 않고 이산적인 것을 뜻합니다. 이 두 핵심을 이용해 요약하면 마르코프 체인은 마르코프 특성을 만족하고 상태의 시간이 이산적으로 변화할 때, 이 시간에 따라 어떤 사건이 발생활 확률이 변화하는 과정을 뜻합니다.
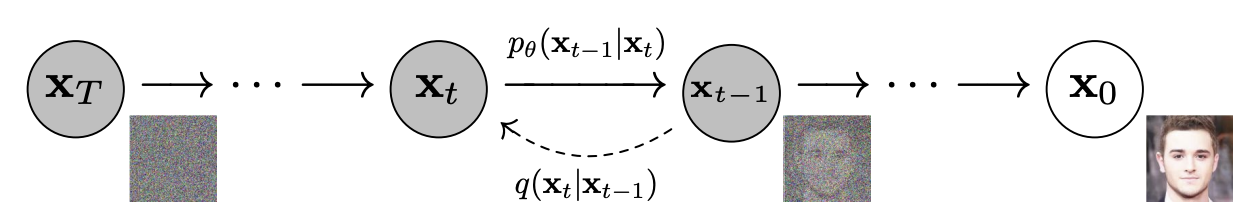
from Denoising Diffusion Probabilistic Models (https://arxiv.org/pdf/2006.11239.pdf) 위의 그림은 diffusion process의 마르코프 체인을 나타낸 것으로, 이전 상태에서 다음 상태로 noise를 추가(점선 화살표)해주는 $q(x_t|x_{t-1})$ 와 noise를 제거하는 과정 $p_θ$$(x_{t-1}|x_t)$는 마르코프 특성을 가정해 다음 상태(latent variable)는 과거 상태와 상관없이 현재 상태에 의해서만 결정됩니다. 여기서 noise를 추가하는 과정을 forward diffusion process라고 하고 반대로 원본 이미지를 재구성하는 과정을 reverse diffusion process라고 합니다. 이때 latent variables $x_1, ..., x_T$에 점진적으로 Gaussian noise를 추가하는 forward diffusion process를 수식으로 표현하면 다음과 같습니다.
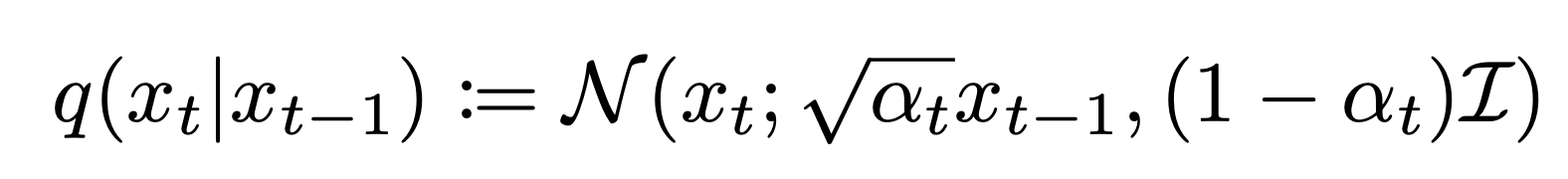
(평균과 분산에 대한 설명은 생략) 위 식이 의미하는 것은 이전 step($t-1$)의 latent variable $x_{t-1}$에서 $√{α_t}$만큼의 signal을 가져오고, $(1-α)$만큼 noise를 추가해서 $x_t$를 계산하는 것입니다. 이때 $(1-α)$이 충분히 작다면, posterior $q(x_{t-1}|x_t)$ 는 diagonal Gaussian으로 approximate 할 수 있습니다.(증명은 blog 참고, 혹은 추후 Diffusion models 포스트에서)
forward diffusion process를 거치면, 즉 time step $t$가 증가하면 원본 이미지($x_0$) 는 점점 손상되고, 결국 $T→∞$ 이면 $x_T$의 분포는 Gaussian distribution이 됩니다.(증명은 blog 참고, 혹은 추후 Diffusion models 포스트에서) 이러한 성질들을 이용하면 true posterior를 approximate 하는 reverse diffusion process 모델 $p_θ$$(x_{t-1}|x_t)$ 를 아래와 같이 표현할 수 있습니다.
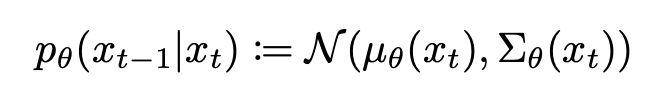
이 모델을 이용해 가우시안 노이즈 $x_T$ ~ $N(0, I)$부터 시작해 점차 노이즈를 줄여나가는 $x_{T-1}, x_{T-2}, ..., x_0$ 과정을 거쳐 원본 이미지와 유사한 $x_0$ ~ $p_θ$$(x_0)$ 를 얻을 수 있습니다. 이러한 generative model을 학습하기 위해 loss를 설정해줘야 하는데, 이 모델은 결국 $x_t$에서 $x_{t-1}$를 얻는 분포를 estimate 하는 것이고 이는 $x_{t-1}$ 상태에서 $x_t$로 noise를 추가하는 $q(x_t|x_{t-1})$ 분포와 유사해지는 것을 뜻합니다. 이를 KL divergence를 이용해 loss 식으로 표현하면 아래와 같이 나타낼 수 있습니다.
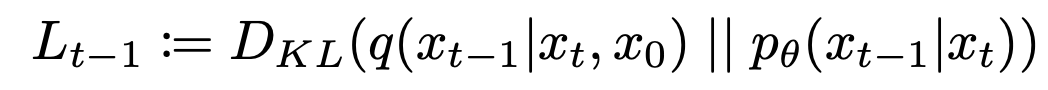
우리는 이러한 과정을 step T부터 0까지 반복하므로 Variationl Lower Bound (VLB)를 아래와 같이 표현합니다.
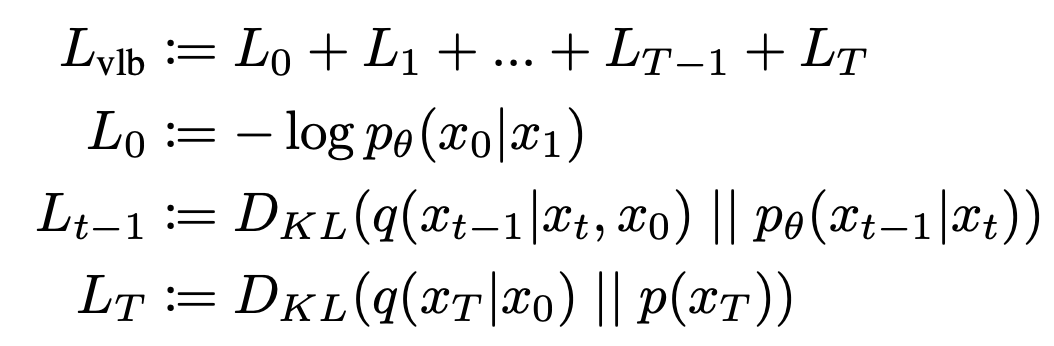
이를 기반으로, DDPM [ Denoising Diffusion Probabilistic Models ]에서 실제로 더 나은 이미지를 생성하는 objective를 제안했습니다. 위에서 $p_θ$$(x_{t-1}|x_t)$를 정의할 때 사용했던 $µ_θ(x_t, t)$을 직접적으로 parameterize 하는 것이 아니라, noise $ε$을 예측하는 모델 $ε_θ(x_t, t)$을 학습하는 것을 제안했고, 이처럼 단순화한 objective를 아래와 같이 표현합니다.
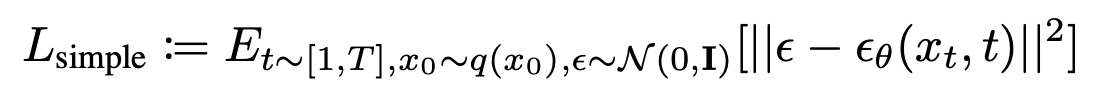
후속 연구로 [ Diffusion Models Beat GANs on Image Synthesis ] 논문에서 적은 diffusion step만으로 더 고화질의 이미지를 생성할 수 있는 모델을 제안했고, GLIDE에서는 여기서 제안한 ADM(Ablated Diffusion Model) 모델을 사용합니다.
Diffusion models은 image super-resolution(저화질 이미지를 고화질 이미지로 변환하는 task)에 적용되어 좋은 성능을 보여주었습니다. GLIDE에서는 이러한 저해상도 이미지를 고해상도 이미지로 upsampling 하는 과정에도 diffusion model을 사용했습니다.

from [ Image Super-Resolution via Iterative Refinement ] 2.2. Guided Diffusion
[ Diffusion Models Beat GANs on Image Synthesis ] 논문에서는 classifier guidance를 받은 class-conditional diffusion models이 생성한 이미지가 더 좋아지는 것을 발견했습니다. 구체적으로는, 이미지 $x_t$가 주어졌을 때 class $y$를 예측하는 분류기를 $p_φ(y|x_t)$라고 할 때, $logp_φ(y|x_t)$의 gradient를 diffusion model의 평균($µ_θ(x_t|y)$과 분산($ Σ_θ(x_t|y)$)에 추가적으로 perturb 했습니다. 그 결과 새로운 perturbed mean은 아래와 같이 표현할 수 있습니다.

여기서 coefficient $s$는 guidance scale이라고 부르며, 이 값을 높일수록 생성되는 이미지의 diversity는 줄어들지만, 이미지의 퀄리티는 증가합니다.
2.3. Classifier-free guidance
최근 [ Classifier-free diffusion guidance ]에서 추가적인 분류기 모델 없이 diffusion model만으로 guiding을 하는 classifier-free guidance 방법을 제안했습니다. 이를 위해 class-conditional diffusion model $ε_θ(x_t, y)$에서 label $y$를 null label $∅$로 대체합니다.
(추후 내용을 추가하겠습니다.)Classifier-free guidance는 두 가지 중요한 특징을 가지고 있습니다. 첫 번째는 추가적인 다른 모델 없이, 하나의 모델로 guidance를 통해 자기 자신의 knowledge를 leverage 한다는 것입니다. 두 번째는 정해진 class를 분류하는 모델로 예측하기 어려운 정보(텍스트로 이루어진 문장 등)를 조건화하여 guidance 가능하게 합니다.
2.4. CLIP Guidance
텍스트와 이미지 사이의 joint representation을 학습할 수 있는 CLIP은 이미지 인코더 $f(x)$와 캡션 인코더 $g(c)$로 이루어져 있습니다. 이미지와 캡션 쌍 $(x, c)$ 으로 이루어진 대용량 데이터셋을 이용해 contrastive learning을 진행합니다. 이때 같은 쌍에서 얻은 이미지와 캡션(같은 의미를 가지는 positive pair)의 임베딩은 서로 가까운 embedding space에 존재하도록(=코사인 유사도가 높아지도록 =내적 $f(x) · g(c)$ 값이 커지도록) 학습하고, 다른 쌍에서 얻은 이미지와 캡션(다른 의미를 가지는 negative pair)에 대해서는 서로 유사도가 낮아지도록 학습합니다.
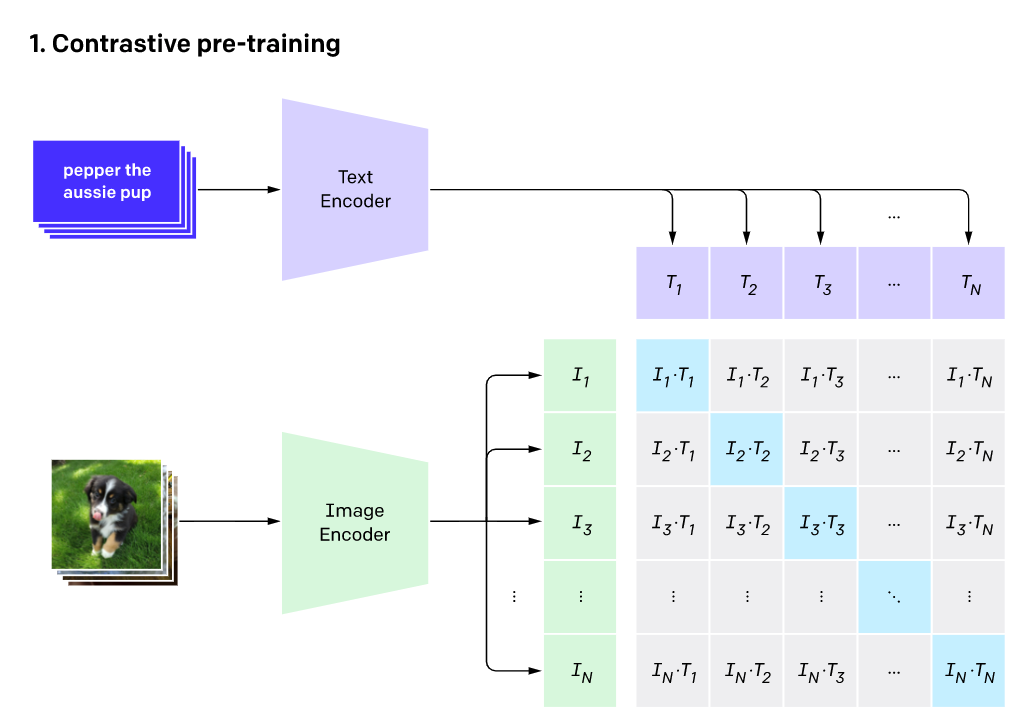
CLIP blog : https://openai.com/blog/clip/ 이러한 방법으로 학습했기 때문에 CLIP은 어떤 이미지와 캡션이 주어졌을 때 둘 사이의 유사도를 계산할 수 있습니다. 최근에는 이를 GAN 같은 생성 모델에서 활용했고, 텍스트를 guidance로 주어 사용자가 원하는 이미지를 합성했습니다. 이러한 아이디어를 diffusion models에 적용해, 위(2.2. Guided Diffusion)에서 소개한 classifier guidance의 분류기 모델을 CLIP 모델로 대체했습니다. 이미지와 캡션 임베딩을 내적한 값의 이미지에 대한 gradient를 구하고, 이를 이용해 reverse diffusion process의 평균에 perturb을 줍니다.
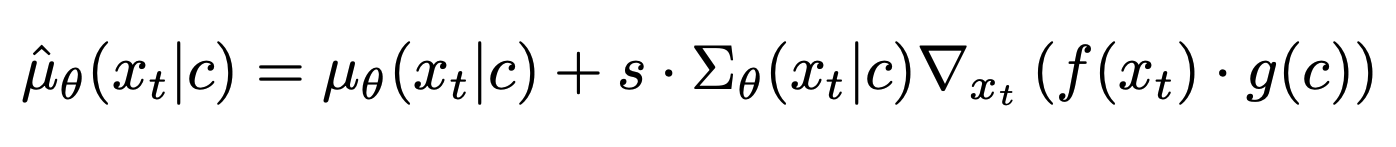
기존 classifier guidance와 유사하게, reverse-process에 올바른 gradient를 얻기 위해 CLIP을 noised 이미지 $x_t$에 대해 학습해야 합니다. 이렇게 noise-aware 상황에서 학습한 CLIP 모델을 noised CLIP 모델이라고 부르겠습니다. 공개된 CLIP 모델로도 guidance를 해봤지만, noised 이미지에 대해 학습을 하지 않았기 때문에 성능이 조금 떨어졌습니다. 저자들은 이에 대해 diffusion process 중간중간에 있는 노이즈 낀 이미지들은 공개된 CLIP 모델에게는 out-of-distribution 이미지들이기 때문인 것 같다고 이야기합니다.
3. Training
저자들은 3.5 billion(35억) 파라미터를 가진 text-conditional diffusion model(64x64 해상도)을 학습했습니다. 그리고 256x256 해상도로 높이기 위해 또 다른 1.5 billion(15억) 파라미터를 가진 text-conditional upsampling diffusion model을 학습했습니다. CLIP guidance를 위해서는 noised 64x64 ViT-L CLIP 모델을 학습했습니다.
3.1. Text-Conditional Diffusion Models
Diffusion Models로는 [ Diffusion models beat gans on image synthesis ]에서 제안한 ADM 모델 구조를 채택했고, 여기에 text conditioning information을 추가로 사용했습니다. 각 noised 이미지 $x_t$ 와 이와 관련된 캡션 $c$에 대하여, 모델은 $p(x_{t-1}|x_t, c)$를 예측합니다.
Text conditioning
텍스트 conditioning을 위해, 캡션을 K개의 token으로 encode 한 뒤 이 토큰들을 Transformer 모델에 forwarding 해 output을 얻습니다. 이 output은 두 가지 방법으로 사용되는데, 첫 번째는 ADM 모델의 class embedding 대신 Transformer output의 마지막 토큰 임베딩을 사용합니다. 코드와 함께 구체적으로 살펴보면,
### https://github.com/openai/glide-text2im ### glide-text2im/glide_text2im/tokenizer/simple_tokenizer.py def end_token(self): return self.encoder["<|endoftext|>"] def padded_tokens_and_len(self, tokens: List[int], text_ctx: int) -> Tuple[List[int], int]: tokens = [self.start_token] + tokens[: text_ctx - 2] + [self.end_token] text_len = len(tokens) padding = text_ctx - len(tokens) padded_tokens = tokens + [0] * padding return padded_tokens, text_len위 과정을 통해 캡션의 끝에 [endoftext] 토큰을 추가해주고
### glide-text2im/glide_text2im/text2im_model.py def get_text_emb(self, tokens, mask): assert tokens is not None if self.cache_text_emb and self.cache is not None: assert ( tokens == self.cache["tokens"] ).all(), f"Tokens {tokens.cpu().numpy().tolist()} do not match cache {self.cache['tokens'].cpu().numpy().tolist()}" return self.cache xf_in = self.token_embedding(tokens.long()) xf_in = xf_in + self.positional_embedding[None] if self.xf_padding: assert mask is not None xf_in = th.where(mask[..., None], xf_in, self.padding_embedding[None]) xf_out = self.transformer(xf_in.to(self.dtype)) if self.final_ln is not None: xf_out = self.final_ln(xf_out) xf_proj = self.transformer_proj(xf_out[:, -1]) xf_out = xf_out.permute(0, 2, 1) # NLC -> NCL위 코드의 마지막 줄 바로 윗줄을 보면 마지막 토큰(xf_out[:, -1])을 projection 하는 것을 알 수 있습니다. 이렇게 마지막 토큰을 linear projection 해서 얻은 feature로 ADM 모델의 class embedding 부분을 대체한 것입니다.
두 번째는 위 코드에서 'xf_out'에 해당하는 K개의 feature vector 시퀀스를 ADM의 attention layer에 projection 해주는 것입니다. 아래 코드의 첫 번째 for문을 보면 input_blocks의 module에 xf_out을 넣어주는 것을 알 수 있습니다.
### glide-text2im/glide_text2im/text2im_model.py def forward(self, x, timesteps, tokens=None, mask=None): hs = [] emb = self.time_embed(timestep_embedding(timesteps, self.model_channels)) if self.xf_width: text_outputs = self.get_text_emb(tokens, mask) xf_proj, xf_out = text_outputs["xf_proj"], text_outputs["xf_out"] emb = emb + xf_proj.to(emb) else: xf_out = None h = x.type(self.dtype) for module in self.input_blocks: h = module(h, emb, xf_out) hs.append(h) h = self.middle_block(h, emb, xf_out) for module in self.output_blocks: h = th.cat([h, hs.pop()], dim=1) h = module(h, emb, xf_out)input_blocks을 살펴보면
self.input_blocks = nn.ModuleList( [TimestepEmbedSequential(conv_nd(dims, in_channels, ch, 3, padding=1))] )TimestepEmbedSequential로 구성된 것을 알 수 있고,
### glide-text2im/glide_text2im/unet.py class TimestepEmbedSequential(nn.Sequential, TimestepBlock): """ A sequential module that passes timestep embeddings to the children that support it as an extra input. """ def forward(self, x, emb, encoder_out=None): for layer in self: if isinstance(layer, TimestepBlock): x = layer(x, emb) elif isinstance(layer, AttentionBlock): x = layer(x, encoder_out) else: x = layer(x) return x위에서 얻은 xf_out이 encoder_out이고, AttentionBlock class를 확인해보면
### glide-text2im/glide_text2im/unet.py if encoder_out is not None: encoder_out = self.encoder_kv(encoder_out) h = self.attention(qkv, encoder_out)attention의 q, k, v 중에서 k, v를 인코딩하는 데 encoder_out(xf_out)을 사용합니다.
정리하면, 캡션을 Transformer에 포워딩하고 그렇게 얻은 output feature를 ADM 모델의 적절한 곳(class embedding 대체, attention)에 사용해 text conditioning을 수행한 것입니다.
DALL-E 1과 같은 데이터셋에서 학습했으며, GLIDE에 사용된 모델들의 구체적인 설정 및 특징은 아래와 같습니다.
전체 학습에 사용된 계산량은 DALL-E 1과 거의 비슷합니다.Base model
ImageNet 64 x 64 model (from 'Diffusion models beat gans on image synthesis' )
- width : 512 channels
- 2.3 billion parameters for the visual part of the model
Transformer (text encoder)
- 24 residual blocks of width 2048
- 1.2 billion parameters
Batch size : 2048
Iteration : 2.5MUpsampling diffusion model
ImageNet upsampler (from 'Diffusion models beat gans on image synthesis' )
- from [64 x 64] to [256 x 256] resolution
- 1.5 billion parameter
- conditioned on text in the same way as the base model
- base channels : 384
Transformer (smaller text encoder)
- width : 1024
Batch size : 512
Iteration : 1.6M3.2 Fine-tuning for classifier-free guidance
위에서 설명한 학습을 끝낸 뒤, base model이 unconditional image generation을 할 수 있도록 fine-tuning을 해주었습니다. 이 과정은 텍스트 토큰 시퀀스 중 20%를 empty 시퀀스로 바꿔준 것 외에는 pre-training 과정과 동일하게 진행합니다. 이를 통해, 모델은 text-conditional 결과를 생성하는 능력을 유지하면서 unconditional 상황에서도 이미지를 생성할 수 있게 되었습니다.
3.3 Image Inpainting
Fine-tuning을 위해 이미지의 random 한 영역을 지우고, 지우고 남은 영역을 마스크 채널(추가 conditioning 정보)과 함께 모델에 포워딩해줍니다. inpainting을 위해 모델은 추가적인 4개의 input channel을 가지고, 이에 해당하는 것이 RGB 채널의 두 번째 set(..?)과 마스크 채널입니다. Fine-tuning 전 이러한 새로운 채널에 대한 입력 가중치는 0으로 초기화합니다. upsampling 모델의 경우 저해상도 이미지는 전체 영역을 모두 사용해 학습하고, 고해상도 이미지의 경우 마스크를 씌우지 않은 영역만 이용합니다. (GLIDE 논문에 나와 있는 부분만으로는 이해가 힘들어 논문에서 언급한 'Palette: Image-toimage diffusion models'을 참고하면 좋을 것 같습니다.)
3.4 Noised CLIP models
Classifier guidance technique을 더 잘 적용하기 위해 CLIP 모델을 noised image $x_t$에 대해서도 기존과 같은 contrastive learning으로 학습시킵니다. 64 x 64 해상도에 대해 학습했고, base model과 같은 noise schedule을 사용합니다.
4. Results

Random image samples on MS-COCO prompts. 4.1 Qualitative Results
저자들은 위 사진뿐만 아니라 여러 결과들에서 CLIP guidance와 classifier-free guidance를 비교해보면 후자가 더 사실적인 이미지를 만들어낸다고 이야기합니다. classifier-free guidance 모델은 그림자나 어딘가에 반사된 모습도 사실적으로 잘 표현하고, 특정한 아티스트나 픽셀 아트 등 여러 화풍의 스타일도 잘 그려낸다고 합니다.
Inpainting task에서 GLIDE는 텍스트를 이용해 기존의 이미지를 매우 사실적으로 수정합니다. 이때 기존 이미지에 없던 새로운 object를 넣는 것이 가능하고, 물에 비친 모습과 빛에 따른 그림자와 같이 사실적인 이미지를 위해서는 필수적인 요소들도 잘 반영합니다. 심지어 그림 속에서 이미지를 수정하면 그 그림의 스타일로 그려진 객체를 추가합니다. 뿐만 아니라 SDEdit을 이용해 실험한 결과, 스케치로부터 이미지를 수정하는 것도 가능함을 보였습니다.

Examples of text-conditional SDEdit (Meng et al., 2021) with GLIDE 4.2. Quantitative Results
여러 metric에 대해 실험을 진행하고, 사람에게 평가를 받아 classifier-free guidance 방법이 CLIP guidance 방법보다 선호됨을 보였습니다. 또한 DALL-E 1(12 billion, 120억 파라미터)과도 비교하여 여러 metric 및 human evaluation에서 GLIDE의 우수성을 입증합니다. GLIDE가 DALL-E 1 보다 작은 모델일 뿐만 아니라 더 적은 latency로 샘플링이 가능합니다. 자세한 결과는 논문을 참고해주시기 바랍니다.
5. Safety Considerations
GLIDE는 전문가가 아니더라도 기존 이미지를 매우 그럴듯하고 빠르게 편집할 수 있도록 도와줍니다. 하지만 그만큼 안전장치 없이 이 모델을 공개하면 Deepfake 나 폭력적인 이미지를 생성하는 등 이롭지 못한 곳에 쓰일 위험이 있습니다. 이러한 잠재적인 위험을 방지하고자 학습 이미지를 필터링하여 데이터셋을 만들고, 더 작은 모델(300M, 3억 파라미터)로 학습하여 GLIDE (filtered)라는 이름으로 오픈소스로 공개했습니다. 물론 이 모델도 몇 가지 편향적인 부분(toys for girs의 결과로 toys for boys 보다 분홍색이 더 많이 들어간 장난감이 나옴 / a religious place의 결과로 서구적인 장소가 더 많이 나옴)이 있음을 발견했습니다. 그 외에도 여러 문제들이 있지만, 연구적인 발전을 위해 GLIDE (filtered) 모델을 공개했고 inpainting 등의 데모도 Github을 통해 사용해 볼 수 있습니다.
6. Limitations
학습 때 자주 일어나지 않은 일이나 복잡한 컨셉의 경우 제대로 묘사하지 못한다는 한계가 있습니다. 또한 unoptimized 모델은 하나의 A100 GPU로 하나의 sample을 뽑는 데 15초나 걸립니다. 이건 GAN과 비교해도 매우 느린 것으로 앞으로 개선이 필요한 부분입니다.
7. Conclusion
DALL-E 2의 decoder 부분에 해당하는 GLIDE를 살펴봤습니다. GLIDE는 기존 GAN의 아성을 깨뜨리고 Diffusion model을 text-to-image domain에 적용해 텍스트를 잘 반영하면서 사실적인 이미지를 생성했습니다. 이미지 inpainting을 이용한 텍스트 기반 이미지 편집 기술의 경우에는 사용처가 굉장히 다양할 것으로 보입니다. 추후에 Github을 통해 공개한 GLIDE (filtered) 모델을 살펴보고 코랩을 이용한 image inpainting 데모도 소개하겠습니다. (ADM 모델에 대한 설명을 위해 'Diffusion models beat gans on image synthesis' 도 리뷰 예정입니다.)
Reference
1. What are Diffusion Models?
2. Generating and editing photorealistic images from text-prompts using OpenAI's GLIDE
3. Generative model - Diffusion model Review
4. 마르코프 프로세스(=마르코프 체인) 제대로 이해하기
5. Hierarchical Text-Conditional Image Generation with CLIP Latents
6. Diffusion Models Beat GANs on Image Synthesis
7. Improved Denoising Diffusion Probabilistic Models
8. Image Super-Resolution via Iterative Refinement
9. Zero-Shot Text-to-Image Generation
10. Classifier-Free Diffusion Guidance
11. Denoising Diffusion Probabilistic Models관련 포스트
[코드 분석] GLIDE 코랩 데모 : Text-guided Image Editing(feat. in-painting)
[코드 분석] GLIDE 코랩 데모 : Text-guided Image Editing(feat. in-painting)
지난 포스트에서 DALL-E 2의 디코더로 사용된 GLIDE에 대해 알아보았습니다. Diffusion models을 Text-to-Image에 적용했으며, 그 결과 텍스트를 잘 반영하는 사실적인 이미지를 생성했습니다. 추가로 텍스
cocoa-t.tistory.com
[논문 리뷰] DALL-E 2 : Hierarchical Text-Conditional Image Generation with CLIP Latents
[논문 리뷰] DALL-E 2 : Hierarchical Text-Conditional Image Generation with CLIP Latents
최근 OpenAI에서 발표한 Text-to-Image 모델 DALL-E 2의 논문을 리뷰하겠습니다. 작년에 발표한 DALL-E 1 보다 더 사실적이면서, 캡션을 잘 반영하는 고해상도(4x) 이미지를 생성해 많은 관심을 받았습니다.
cocoa-t.tistory.com
728x90'Machine Learning > Multimodal Learning' 카테고리의 다른 글