-
[논문 리뷰] Imagen: Photorealistic Text-to-Image Diffusion Models with Deep Language UnderstandingMachine Learning/Multimodal Learning 2022. 5. 25. 00:02728x90
최근 구글에서 발표한 Text-to-Image diffusion model 입니다. (최근 diffusion model의 강세가 주목할 만합니다)
OpenAI에서 공개한 DALL-E 2와 같이 텍스트를 기반으로 사실적인 이미지를 생성해내는 모델로,
"Unprecedented photorealism × Deep level of language understanding"
라는 슬로건으로 전례없이 사실적인 이미지를 생성하며, 언어에 대한 깊은 이해가 가능함을 강조했습니다.
예시를 통해 Imagen의 생성 능력을 살펴보고, 논문을 통해 어떻게 이런 능력을 가질 수 있는지 알아보겠습니다.
[ paper | blog ]
Abstract
Imagen은 두 개의 강력한 모델로 이루어져 있습니다. 바로 뛰어난 언어 이해력을 가진 Transformer 기반의 라지스케일 언어 모델과 고품질의 이미지를 생성할 수 있는 diffusion models 인데요. 여기서 재미있는 발견은, Imagen이 사용한 언어 모델은 이미지 없이 텍스트 만으로 사전학습된 모델(T5)로, 이미지 생성을 위한 텍스트 인코딩에서 놀라운 효과를 보여주었다는 것입니다. 심지어 이미지 diffusion model의 사이즈를 키웠을 때보다, 언어 모델의 사이즈를 키웠을 때 이미지의 품질과 이미지와 텍스트 사이의 alignment가 더 좋아지는 것을 확인했습니다.
Imagen은 COOC 데이터셋에 대한 FID score에서 7.27로 새로운 SOTA를 달성했고, 이는 COCO 데이터셋에 대한 학습 없이 얻은 결과입니다. 저자들은 text-to-image 모델을 더욱 깊이 평가하기 위해 DrawBench라는 새로운 벤치마크를 소개했습니다. 이 벤치마크에 대해서 최근 발표된 GLIDE, DALL-E 2와 같은 모델과 비교했을 때, human rater들은 생성된 이미지의 품질과 이미지-텍스트 alignment에 대해서 Imagen의 결과에 더 높은 선호도를 보였습니다.
Imagen 모델의 전체 구조. 텍스트 인코더(blue)로 frozen T5-XXL를 사용, 64x64 이미지를 생성하는 Text-to-Image diffusion model과 2개의 super-resolution diffusion모델을 사용해 최종적으로 1024x1024 이미지 생성
Key Contribution
1. 텍스트 만으로 학습한 라지스케일 언어 모델(frozen)을 텍스트 인코더로 사용했을 때 이미지 생성에 매우 효과적임을 밝힙니다. 더 나아가 이미지 diffusion model 보다 텍스트 인코더 사이즈를 키우는 것이 품질 향상에 더 도움이 됩니다.
2. 새로운 diffusion 샘플링 기법인 dynamic thresholding 을 제안합니다. (뒤에서 설명)
3. 몇 가지의 중요한 diffusion architecture 설계 요소를 강조하고, 간단하면서 memory efficient 하고 빠르게 수렴하는 Efficient U-Net 구조를 새롭게 제안합니다.
4. COCO FID에서 7.27로 새로운 SOTA를 달성하고, 평가자(human raters)들은 Imagen이 이미지-텍스트 alignment 측면에서 reference와 거의 동등하다고 이야기합니다.
5. Text-to-Image task의 새로운 평가 벤치마크인 DrawBench를 소개합니다. 이는 매우 포괄적이고 challenging한 벤치마크로, 평가자들은 Imagen이 다른 모델들(DALL-E 2 등)에 비해 더 우수함을 확인했습니다.
Example

(왼쪽) 올림픽이라는 설정에 맞게 바다나 호수가 아닌 수영장에서 수경, 모자를 쓰고 수영하는 모습을 생성합니다.
(오른쪽) 초밥으로 만든 집이 실제로는 존재하지 않지만 문맥에 맞게 생성했습니다.
(왼쪽) karate belt를 한 dragon fruit만 말했지만 눈, 입과 포즈를 취하고 있는 손으로 의인화해 표현했습니다.
(오른쪽) 딸기 컵 자체도 사실적이지만 어두운 초콜릿 바다에 반사된 모습까지 매우 사실적으로 생성합니다.
(왼쪽) 안드로이드 마스코트가 무엇인지 이해하고 있고, 대나무의 특징도 잘 반영합니다.
(오른쪽) 단어 하나하나를 놓치지 않고 다 표현했습니다. (종이접기, 여우, 유니콘, 눈 오는 숲)
한 문장이 아니라 여러 문장의 텍스트 인풋도 이해하고 반영해 이미지를 생성합니다.

(왼쪽) 초콜릿 파우더, 망고, 휘핑크림의 특징을 살리면서 자연스럽게 대머리 독수리의 이미지를 생성합니다.
(오른쪽) 코알라 DJ, 턴테이블, 헤드폰까지 모두 대리석 조각상으로 꽤나 사실적으로 그려냅니다.
(왼쪽) 찍은 사진이라고 해도 부정하기 힘들 것 같습니다.
(오른쪽) 모네 그림이 전시되어 있는 아트 갤러리가 침수되어 로봇들이 패들 보드를 타고 있습니다..소개한 이미지 외에도 논문과 블로그를 보면 왜 "Unprecedented photorealism × Deep level of language understanding" 라는 슬로건을 선택했는지 납득이 갑니다. 물론 cherry pick 결과겠지만, 이전에 공개된 text-to-image 모델들의 경우 긴 문장에 대해 생성한 이미지가 거의 없었다는 점을 감안하면 언어 이해의 능력을 많이 향상한 것을 알 수 있습니다.
Imagen
1. Pretrained text encoders
Text-to-Image 모델은 자연어 텍스트 입력의 복잡성과 구성성(compositionality)을 파악해야하고, 이를 위해서는 문장의 의미를 이해할 수 있는 강력한 텍스트 인코더가 필요합니다. 지금까지는 이러한 텍스트 인코더를 이미지-텍스트 쌍의 데이터에서 학습하는 것이 표준이었습니다. 하지만 이미지-텍스트 쌍 데이터보다 텍스트 만으로 이루어진 말뭉치 데이터는 더우 풍부하고 광범위한 텍스트 분포를 갖고 있고, 라지스케일 언어 모델 자체의 파라미터 수도 최근 이미지-텍스트 모델들과 비교해 훨씬 더 큽니다. 예를 들어, PaLM(text only)은 540B(5400억) 파라미터를 가지고 있고, CoCa(image-text)는 약 1B(10억) 파라미터의 텍스트 인코더를 가집니다
따라서 이미지-텍스트 데이터셋으로 학습한 텍스트 인코더 뿐만 아니라 텍스트 만으로 학습된 텍스트 인코더를 Text-to-Image 모델에 적용해보는 것은 자연스러우며, 저자들은 BERT, T5, CLIP에 대해서 모두 실험해 보았습니다. 이때 텍스트 인코더들은 모두 이미 사전학습되어 있는 모델을 가져오며, 추가적인 학습은 하지 않고 freeze 합니다. 그 결과 실험을 통해 텍스트 인코더의 크기를 키워 이미지 생성 품질이 향상될 수 있다는 것을 발견했습니다.
2. Diffusion models and classifier-free guidance
Diffusion model은 가우시안 노이즈를 반복적인 디노이징 과정을 거쳐 학습된 데이터의 분포(이미지)로 변환하는 생성 모델입니다. 이런 모델들은 class label이나 텍스트, 혹은 저해상도 이미지로 조건화(conditional, 조건으로 주는 인풋에 따라 아웃풋이 달라짐) 할 수 있습니다. diffusion model ˆxθ는 아래와 같은 denoising objective로 학습됩니다.
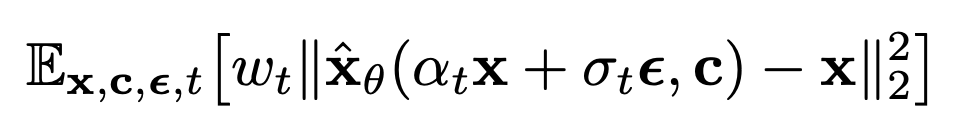
(x,c) 는 data-conditioning pairs이며, t~U([0,1]), ϵ~N(0,I)(가우시안 노이즈) 입니다. 그리고 αt,σt,wt는 샘플 품질에 영향을 주는 t에 대한 function들 입니다. 직관적으로, diffusion model은 squared error loss로 노이즈가 있는 zt:=αtx+σtϵ를 x로 디노이징 하도록 학습하는 것입니다. (Text-to-Image diffusion model에 대해 GLIDE 논문 리뷰에서 비교적 자세히 다뤘으니 참고하시면 좋을 것 같습니다.)
[Diffusion models beat gans on image synthesis]에서 소개된 Classifier guidance기법은 diffusion model이 샘플링할 때 사전학습된 모델 p(c|zt)의 gradients를 이용해 샘플 품질을 높이고, condition에 맞게 diversity를 줄입니다. 하지만 이는 사전학습된 모델을 필요로 하기 때문에 이러한 한계를 개선한 Classifier-free guidance [Classifier-free diffusion guidance]가 제안되었습니다.
이 기법은 훈련 중 condition c를 랜덤(10% 확률)으로 제거해 하나의 diffusion model이 conditional과 unconditional objectives에 대해 jointly 학습합니다. 샘플링은 조정된 x-prediction (zt−σˆϵθ)/αt 을 사용해 수행되는데 이 때 ˆϵθ 는 아래와 같습니다. (x-prediction은 위에서 언급한 zt:=αtx+σtϵ 에서 x를 좌변으로 옮기고 나머지를 우변으로 옮겨 정리했을 때의 식이며, ϵ을 아래와 같이 조정했기 때문에 adjusted x-prediction이라고 부릅니다.)
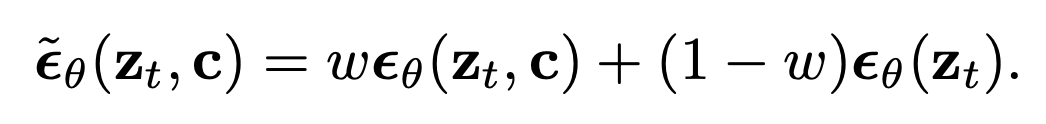
여기서 ϵθ(zt,c) 는 conditional, ϵθ(zt) 는 unconditional ϵ-predictions이며, ϵθ:=(zt−αtˆxθ)/σt 이고, w는 guidance weight 입니다. classifier-free guidance에서는 w=1은 불가능하며, w>1로 증가하면 guidance의 효과를 강하게 해주는 것입니다. Imagen은 효과적인 텍스트 컨디셔닝을 위해 classifier-free guidance에 크게 의존합니다.
3. Large guidance weight samplers
ing..
728x90'Machine Learning > Multimodal Learning' 카테고리의 다른 글
