-
[개념 정리] 3. 하둡 분산 파일 시스템(HDFS) 이해 (2)Big Data/Hadoop 2022. 5. 17. 23:19728x90
Keyword : Rack Awareness, Safe mode, Block corruption, Hadoop 2.0 Cluster Architecture, High Availability
개인적인 공부를 위해 강의를 정리한 내용입니다. 이번 글에 포함되어 있는 많은 이미지 또한 해당 강의에서 발췌했습니다.
하둡을 처음 공부하시는 분들은 강의 시청을 추천드립니다.Rack Awareness

블록을 저장할 때, 2개의 블록은 같은 Rack에, 나머지 하나의 블록은 다른 Rack에 저장하도록 구성합니다. 이는 전원이나 스위치 고장 등 Rack 단위의 장애가 발생했을 때 전체 블록이 유실되는 것을 방지합니다.
HDFS 세이프 모드
세이프 모드(safemode)는 데이터 노드를 수정할 수 없는 상태를 뜻합니다. 세이프 모드가 되면 데이터는 읽기 전용 상태가 되고, 데이터를 추가하거나 수정할 수 없고, 또한 데이터 복제도 일어나지 않습니다. 관리자가 서버 운영 정비를 위해 세이프 모드를 설정할 수 있으며, 네임노드에 문제가 생겨 정상적인 동작을 할 수 없을 때에도 자동으로 세이프 모드로 전환됩니다. 주로 missing block(replication이 디폴트가 3인데, 2만 가지고 있다면 Under replicated, 하나도 없다면 missing block)이 발생하는 경우, 혹은 클러스터 재구동 시 블록 리포트를 다 받기 전까지 세이프 모드로 동작합니다. 세이프 모드 상태일 때 파일 복사를 시도하면 아래와 같으 에러가 발생합니다.
$ hadoop fs -put ./sample.txt /user/sample.txt put: Cannot create file/user/sample2.txt._COPYING_. Name node is in safe mode.HDFS 세이프 모드 명령어 및 복구
# 세이프 모드 상태 확인 $ hdfs dfsadmin -safemode get Safe mode is OFF # 세이프 모드 진입 $ hdfs dfsadmin -safemode enter Safe mode is ON # 세이프 모드 해제 $ hdfs dfsadmin -safemode leave Safe mode is OFFHDFS 운영 중 safe mode에 진입한 경우, 네임노드의 문제인지 데이터노드의 문제인지 파악해야 하며, 'fsck' 명령으로 HDFS의 무결성을 체크하고, 'hdfs dfsadmin -report' 명령으로 각 데이터 노드의 상태를 확인하여 문제를 해결한 후 세이프 모드를 해제해야 합니다.
Block Corruption
HDFS는 heartbeat를 통해 데이터 블록에 문제가 생기는 것을 감지하고 자동으로 복구를 진행합니다. 다른 데이터 노드에 복제된 데이터를 가져와 복구하지만, 모든 복제 블록에 문제가 생겨 복구하지 못하게 되면 커럽트 상태가 됩니다. 커럽트 상태의 파일들은 삭제하고, 원본 파일을 다시 HDFS에 올려주어야 합니다.
heartbeat : 데이터노드가 네임노드에 3초마다 보내는 정보로 디스크 가용 공간정보, 데이터 이동, 적재량 등의 정보를 포함합니다. 10초 이상 못 받으면 해당 데이터노드를 사용하지 못한다고 인식합니다.
HDFS 휴지통 설정
데이터 삭제 시 영구적으로 데이터를 삭제하지 않도록 휴지통(trash)을 설정할 수 있습니다. 언제까지 휴지통으로 보낸 정보를 가지고 있을지도 지정할 수 있습니다.
HDFS 운영자 커맨드
dfsadmin -report
각 노드들의 상태를 출력하며, HDFS 전체 사용량과 각 노드의 상태를 확인할 수 있습니다.
dfsadmin -setQuota
특정 디렉토리는 어떤 팀에게만 저장, 복사 등을 할 수 있게 가이드를 해줬을 때, 그 디렉토리 용량을 제한하기 위해 쿼터 설정을 사용합니다.
특정 디렉토리에 용량 Quota를 설정, n의 단위는 bytes
$sudo -u hdfs hdfs dfsadmin -setSpaceQuota n directory특정 디렉토리에 용량 Quota 설정을 해제
$sudo -u hdfs hdfs dfsadmin -clrSpaceQuota directoryHDFS Balancers
하둡을 운영하다보면, 도입 시기에 따라 하드웨어의 스펙이 달라지고 이로 인해 서로 다른 스펙의 데이터노드를 하나의 클러스터로 구성하게 됩니다. 이 경우 노드 간 디스크 크기가 다를 수 있고, 그 결과 전체 데이터가 제대로 밸런싱이 되지 않는 문제가 발생할 수 있습니다. 하둡 3.0에서는 이러한 밸런싱 문제를 어느 정도 개선했지만, 사용자가 직접 밸런싱을 관리할 때는 많은 주의를 해야 합니다.
WEB HDFS REST API
REST API를 이용해 파일을 조회, 생성, 수정, 삭제하는 기능을 제공합니다.
REST - Representational State Transfer (참고)
자원의 이름(자원의 표현)으로 구분하여 해당 자원의 상태(정보)를 주고 받는 것
HTTP URI를 통해 자원을 명시하고, HTTP Method(POST, GET, PUT, DELETE)를 통해 해당 자원에 대한 CRUD(Create, Read, Update, Delete) Operation을 적용하는 것을 의미이 기능을 이용해 원격지에서 HDFS의 내용에 접근하는 것이 가능합니다.
Hadoop 2.0 Cluster Architecture
마스터 서버의 장애를 해결하기 위한 개선이 가장 큰 변화입니다.
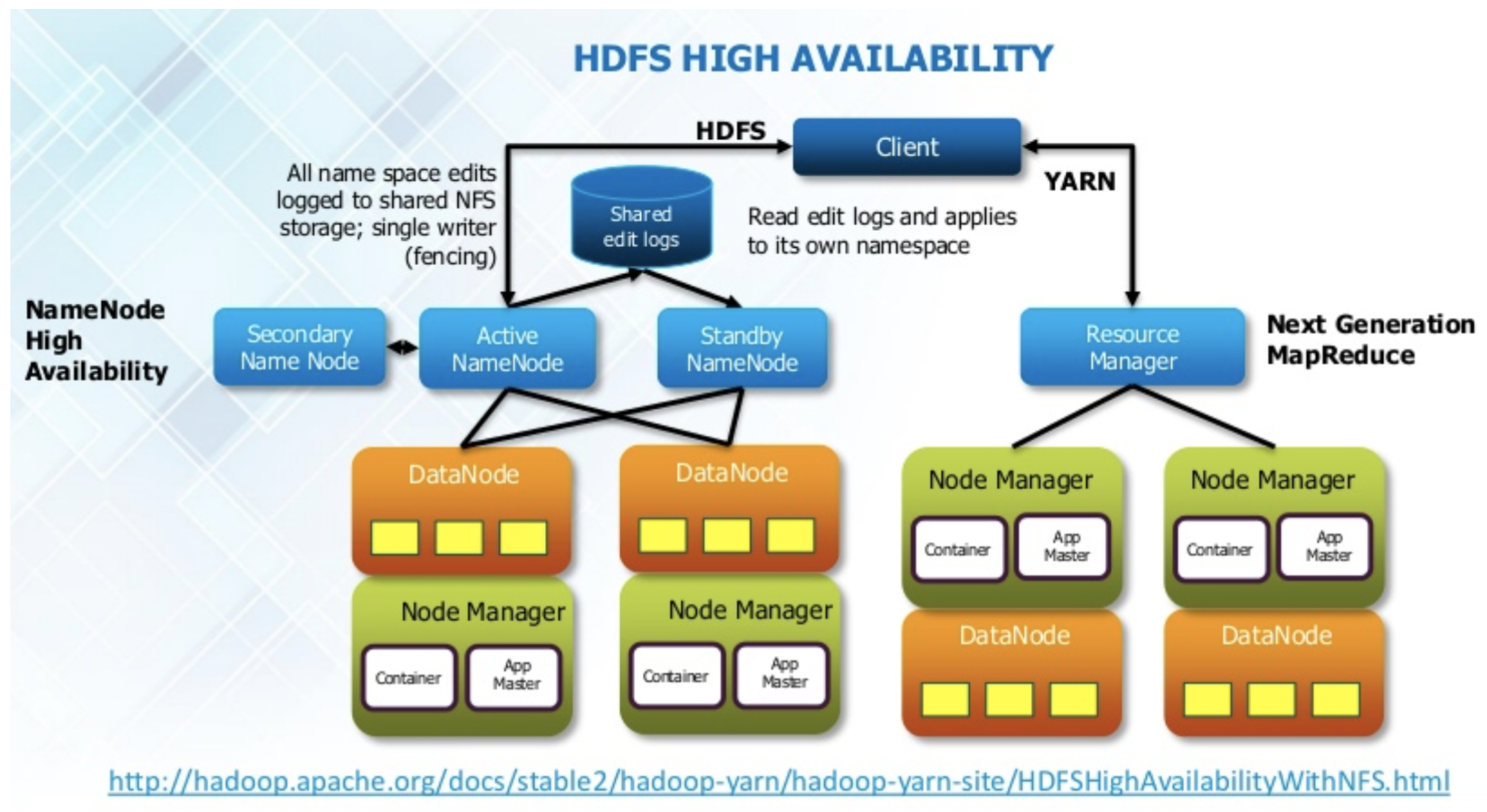
기존에는 NameNode에 장애가 발생하면 모든 클라이언트가 HDFS를 사용할 수 없게 되고(SPOF-Single Point of Failure) 이러한 문제를 개선해 고가용성(High Availability)을 위해 Hadoop 2.0에는 기존에 없던 Standby NameNode가 추가되었습니다. 이 노드의 경우 평소에 정보는 가지고 있지만 동작하지 않다가 Active NameNode가 다운됐을 때 Standby NameNode가 액티브로 전환됩니다. 위의 이미지에서 Shared edit logs가 중요한데, 이에 대해서 뒤에서 자세히 다루겠습니다.
네임노드 고가용성 (High Availability)
HDFS 고가용성은 이중화된 두 대의 서버인 액티브 네임노드와 스탠바이 네임노드를 이용해 지원합니다. 액티브 네임노드와 스탠바이 네임노드는 데이터 노드로부터 블록 리포트와 heartbeat 모두 받아서 동일한 메타데이터를 유지하고, 공유 스토리지를 이용해 에디트 파일을 공유합니다. 액티브 네임노드는 네임노드의 역할을 수행하고, 스탠바이 네임노드는 액티브 네임노드와 동일한 메타데이터 정보를 유지하다가 액티브 네임노드에 문제가 생기면 대체하여 액티브 네임노드로 동작합니다. 액티브 네임노드에 문제가 발생하는 것을 자동으로 확인하는 것이 어렵기 때문에 보통 주키퍼(ZooKeeper)를 이용해 장애 발생 시 자동으로 변경될 수 있도록 구성합니다.
에디트 로그 공유 방식 1: NFS(Network File System) - ex) NAS
NFS를 이용하는 방법은 에디트 파일을 공유 스토리지를 통해 공유하는 것입니다. 공유 스토리지에 에디트 로그를 공유하고, 펜싱(fencing, 네임노드를 확실하게 다운시키는 것, 액티브를 전환하도록 하는 기능)을 이용해 하나의 네임노드만 에디트 로그를 기록합니다.
하지만 이러한 NFS 공유 방식에는 문제점이 있는데요. 네임노드 두 개가 모두 액티브 될 수 있으며, 동시에 Shared Storage(공유 스토리지)의 데이터를 수정하면 네임노드의 중요 정보가 Crash 될 수 있습니다. 분산 환경에서는 이 상태를 SplitBrain이라고 합니다. 두 개의 액티브 네임노드가 발생하는 상황을 막기 위해 설정을 통해 액티브 네임노드를 kill 하거나 공유 스토리지를 unmount 해줍니다. 하지만 네트워크 장애의 경우, 기존 액티브 네임노드가 ZooKeeper와 스탠바이 네임노드로만 통신이 되지 않고, 공유 스토리지와 통신이 되는 상황이 발생할 수 있습니다. 이런 경우 스탠바이 네임노드에서 펜싱 처리는 네트워크 단절로 인해 수행할 수 없고, 기존 액티브 네임노드는 여전히 살아있는 상태가 됩니다.
에디트 로그 공유 방식 2: Journal Node 그룹 사용(디폴트)
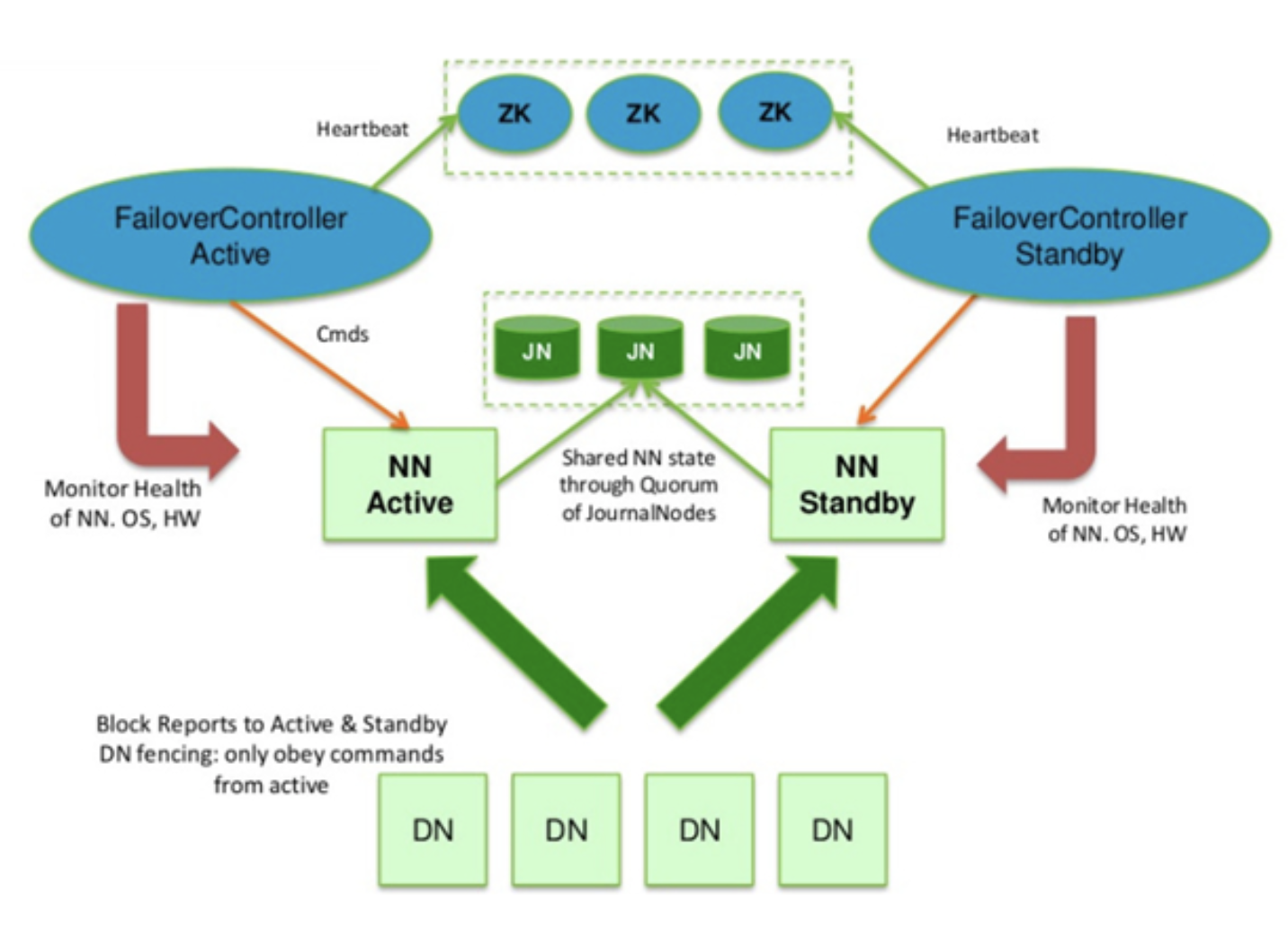
QJM(Quorum Journal Manager)은 네임노드 내부에 구현된 HDFS 전용 구현체로, 고가용성 에디트 로그를 지원하기 위한 목적으로 설계되었습니다. 액티브 네임노드는 클라이언트로부터 파일 시스템 쓰기(업데이트, 삭제, 이동 등) 요청을 받으면 저널노드(JournalNode)에 접근해 해당 트랜잭션(edit log 내용)을 전송하고 저장을 요청합니다. 저널노드는 네임노드로부터 받은 트랜잭션을 저널 노드 자신의 로컬 디스크에 저장합니다. 해당 edit log 내용은 전체 저널 노드들에 동시에 쓰여집니다.(참고)
Journal Node 사용 시 Failover 절차
1. 액티브 네임노드는 edit log 처리용 epoch number를 할당받습니다. 이 번호는 unique 하게 증가하는 번호로 새로 할당받은 번호는 이전 번호보다 항상 큽니다.
2. 액티브 네임노드는 파일 시스템 변경 시 저널노드로 변경 사항을 전송합니다. 전송 시 epoch number를 같이 전송합니다.
3. 저널노드는 자신이 가지고 있는 epoch number 보다 큰 번호가 오면 자신의 번호를 새로운 번호로 갱신하고 해당 요청을 처리합니다.
4. 저널노드는 자신이 가지고 있는 번호보다 작은 epoch number를 받으면 해당 요청은 처리하지 않습니다. 이러한 요청은 주로 SplitBrain 상황에서 발생하게 됩니다. 즉, 기존 네임노드가 정상적으로 스탠바이로 변하지 않았고, 이 네임노드가 정상적으로 펜싱 되지 않은 상태입니다.
5. 스탠바이 네임노드는 주기적으로(1분) 저널노드로부터 이전에 받은 edit log의 txid(Transaction Identification, 하나의 트랜잭션을 다른 트랜잭션과 구별할 수 있도록 특정 트랜잭션에 부여한 아이디) 이후의 정보를 받아 메모리의 파일 시스템 구조에 반영합니다.
6. 액티브 네임노드에 장애가 발생하면 스탠바이 네임노드는 마지막으로 받은 txid 이후의 모든 정보를 받아 메모리 구성에 반영한 후, 액티브 네임노드로 상태를 변환합니다.
7. 새롭게 액티브 네임노드가 되면 1번 항목을 처리합니다.
HDFS Federation
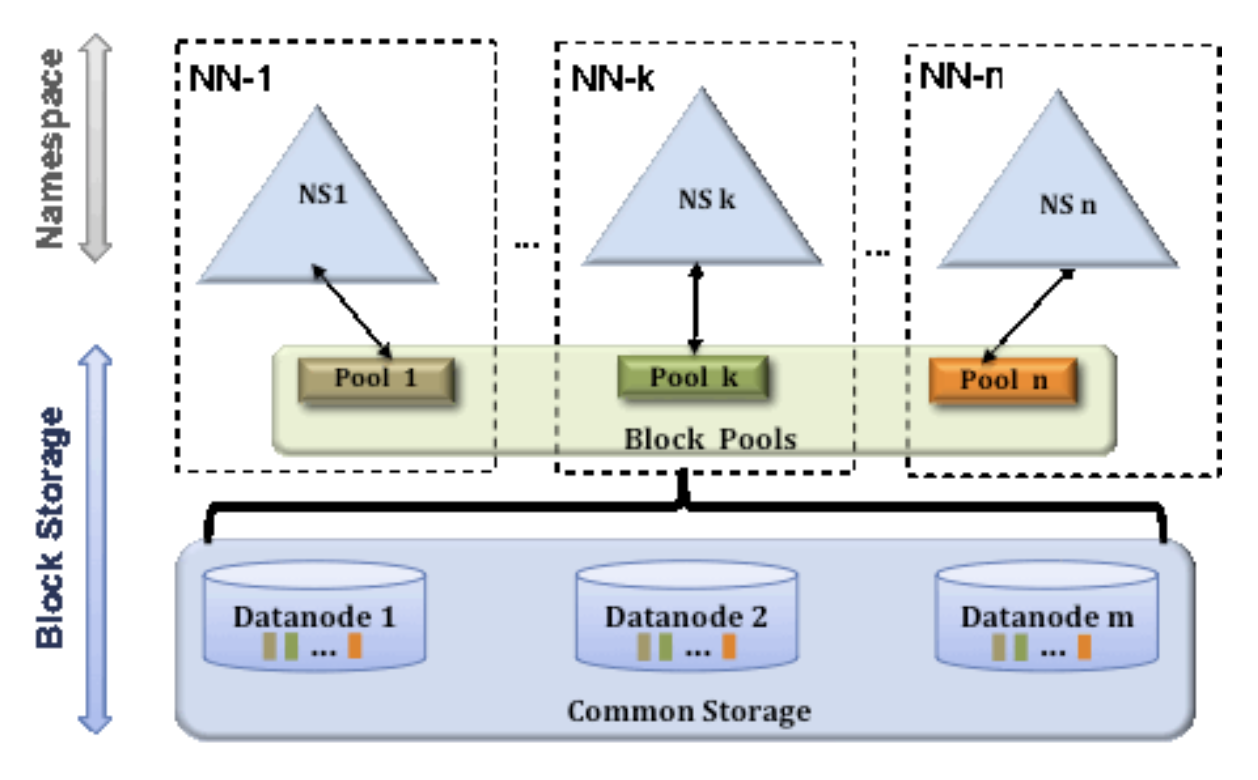
하나의 네임노드에서 관리하는 파일 혹은 블록의 개수가 많아지면 물리적으로 한계에 도달할 수 있습니다. (메모리 보다 처리해야 하는 데이터가 많아질 경우) 이를 해결하기 위해 하둡 2.0 이상에서는 HDFS Federation을 지원합니다. 이를 사용하면 파일, 디렉토리의 정보를 가지는 네임스페이스와 블록의 정보를 가지는 블록 풀을 각 네임노드가 독립적으로 관리하게 됩니다. 네임 스페이스와 블록 풀을 네임스페이스 볼륨이라고 하고, 네임스페이스 볼륨은 독립적으로 관리되기 때문에 하나의 네임노드에 문제가 생겨도 다른 네임노드에 영향을 주지 않습니다.
아파치 주키퍼(ZooKeeper)란?

주키퍼는 분산 시스템의 코디네이터로, 주로 아래와 같은 목적으로 사용됩니다.
1) 설정 관리 (Configuration Management)
2) 분산 클러스터 관리 (Distributed Cluster Management)
3) 명명 서비스 (Naming Service: e.g. DNS)
4) 분산 동기화 (Distributed Synchronization : locks, barriers, queues)
5) 분산 시스템에서 리더 선출 (Leader selection in a distributed system)
6) 중앙집중형 & 신뢰성 있는 데이터 저장소 (Centralized and highly reliable data registry)아파치 주키퍼 데이터 구성
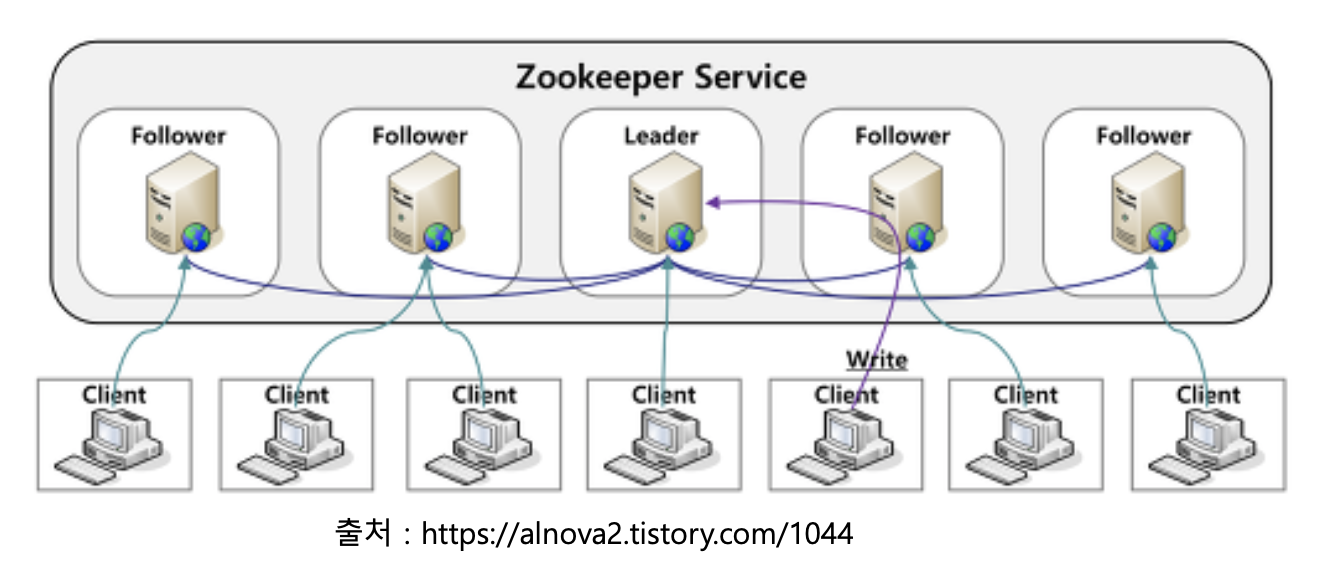
주키퍼는 n개의 서버로 단일 클러스터를 구성하며, 이를 서버 앙상블 이라고 합니다. 주키퍼 서비스는 복수의 서버에 복제되며, 모든 서버는 데이터 카피본을 저장합니다. Leader는 구동 시 주키퍼 내부 알고리즘에 의해 자동으로 선정되며, Followers 서버들은 클라이언트로부터 받은 모든 업데이트 이벤트를 리더에게 전달합니다. 클라이언트는 모든 주키퍼 서버에서 읽을 수 있으며, 리더를 통해 쓸 수 있고 과반수 서버의 승인(합의)이 필요합니다.
728x90'Big Data > Hadoop' 카테고리의 다른 글
[개념 정리] 하둡 MapReduce 이해 (2) (0) 2022.05.22 [개념 정리] 하둡 MapReduce 이해 (1) (0) 2022.05.20 [개념 정리] 2. 하둡 분산 파일 시스템(HDFS) 이해(1) (0) 2022.05.14 [개념 정리] 1. 하둡의 탄생과 생태계의 활용 (0) 2022.05.10
